AgentLens: The Future of Evaluation is Agentic




The ideal evaluation system should surface failure modes and usage patterns, provide actionable insights, adapt to your product and improve over time. Nothing out there met our eval needs. So we built AgentLens: a multi-agent system which surfaces deeper insights and continuously learns what matters for your product. Check out some of the dashboards produced by AgentLens: example1 example2
Introduction
"How did we miss this?!" your manager asks. You shipped your agent three months ago. There's been a steady stream of users and no major incidents. You're already planning the next feature release.
But then, on a Tuesday morning, everything changes. Usage metrics are dropping. A few support tickets come in, your biggest customer calls to complain—but most users aren't saying anything. They're just leaving.
By noon, you're sitting in a conference room with your manager, the VP of Product, Head of Sales, the CTO, and—great—the CEO. You dig into the logs and find patterns: citations break inside generated tables. Users have been trying the agent for tax preparation—which it wasn't designed for—and silently churning when it fails.
You try to explain. You ran benchmarks, and the agent scored in the 85th percentile, but the benchmarks didn't test tax policy questions. You wrote LLM-as-judge prompts to check quality, but the LLM-as-judge can only test for problems that you've already anticipated, not this tax evaluation problem. You even paid for human evaluation on thousands of traces, but the annotators didn't confer among themselves to discuss failures or surface trends.
You had the data. You just couldn't see the patterns until it was too late.
"So add tests for those specific cases," the Head of Sales says. "That fixes these issues," you reply. "But next week it'll be something else. What if we ship an update and break something we didn't test for? We can't solve this by adding more test cases. We need an evaluation method that adapts—that continuously learns what matters and evolves as the product changes."
Silence.
Then the CEO speaks: "What would it actually take to catch this before it happens?"
You've thought about this. "We'd need continuous, comprehensive evaluation. Not spot-checking samples or running benchmarks quarterly. We need to actually understand how the system behaves across thousands of interactions, clustering failures into patterns, maintaining criteria that evolve as users find new edge cases."
"So hire more people," the Head of Sales says. "That's the problem. Evaluation doesn't scale linearly with people. The bottleneck isn't running tests—it's making sense of the results. You need specialists who can spot patterns across disparate failure modes, translate vague user complaints into evaluation criteria, understand what matters versus what's noise. And you need this to happen continuously, not in two-week annotation cycles."
The CTO leans forward. "What if you could do that systematically? Make evaluation as iterative as debugging?"
At Contextual AI, we built AgentLens to make evaluation as fast and iterative as debugging—something one engineer can drive instead of requiring coordination across teams and annotation cycles.
Explore the generated dashboards yourself!
Solution
AgentLens is a dynamic, multi-agent evaluation system that provides two things previous methods couldn't: deeper insights and true adaptability.
It evaluates individual samples with the nuance of human judgment, mines patterns across thousands of interactions to surface trends you'd never spot manually, and automatically generates visualizations tailored to your data. And because evaluation criteria shouldn't stay static, the system continuously learns what matters — evolving as you provide feedback, as your product changes, as users encounter new edge cases.

How it works. The system consists of three agent layers working in sequence:
- MetricAgents evaluate individual traces across multiple dimensions (e.g., groundedness, instruction following using LMUnit as a tool, query classification, etc), using dynamic agents that assess each sample in the context of your guidelines. They produce not just scores, but reasoning, examples, and surfaced insights at the trace level.
- InsightMiners review sample-level scores to find systemic patterns and trends—either by writing code for statistical analysis or through agentic map-reduce. This is where "citations break inside tables" or "tax questions fail 3x more often" gets discovered.
- SynthesisAgents form the final outputs: actionable insights and visualizations that understand the holistic context of your system. They select the right chart types, craft narratives around the data, and surface concrete recommendations for improvement.
Each layer operates independently but communicates and flexibly shares data, so insights flow from individual traces up to high-level dashboards. Take the tax issue from the intro: you never anticipated tax queries and never told the system to look for them. But one MetricAgent flags these as out-of-distribution while another scores them low on instruction-following; one InsightMiner notices a growing cluster of similar OOD queries while another finds that low-performing traces disproportionately involve policy questions; a SynthesisAgent connects the dots, tests the correlation, and surfaces a visualization to your dashboard—before users start churning.
But of course, evaluation isn't one size fits all. What ties it all together and adapts the system to your specific needs is the Evaluation Spec.
The Evaluation Spec. At the heart of the system is the Evaluation Spec: a living representation of what matters for your product. It's the accumulated context of how you want your system to be evaluated—your requirements, your definition of quality, and patterns you've flagged over time. Every component of the system, from trace-level scoring to dataset-level analysis, is grounded in this Spec.
What makes this powerful: you can update the Eval Spec through natural language feedback at any level. Notice something off in a dashboard? Flag a sample as incorrect? Want to explore a correlation? The system reasons about your feedback and updates the Spec accordingly—like having a product manager who translates rough observations ("responses seem verbose when there are tables") into precise evaluation criteria that propagate throughout the entire system.
Deeper Insights
We wanted to test whether AgentLens could surface meaningful insights across very different evaluation contexts, not just one narrow domain. So we evaluated an LLM on SWE-Bench and an agent on BrowseComp: one structured and code-centric, the other interactive and open-ended. If AgentLens can work effectively at evaluating both, it can adapt to your use case too.
Each evaluation is shaped by its own Eval Spec. What matters for code repair is different from what matters for web navigation, and the system adapts its metrics, analysis, and visualizations accordingly.
AgentLens runs autonomously and produces full interactive dashboards. Not just a score. Not just a rationale. A complete dashboard with insights, visualizations, and recommendations tailored to what actually matters for your system. See for yourself: [SWE-Bench] | [BrowseComp]
Let’s take a look at some example visualizations produced by AgentLens after reviewing Sonnet-4.5's outputs on SWE-Bench:
Insight 1: Smaller patches succeed more often.

The scatter plot visualizes 225 automated code repair attempts, showing the relationship between patch size (lines added) and patch modifications (lines deleted). Each point is colored by outcome: green for success, yellow for partial success, pink for failure. AgentLens detected this correlation, chose the scatter plot format, and added marginal histograms to make the pattern visible. The takeaway: smaller edits cluster toward success, larger patches scatter toward failure.
Insight 2: Token Truncation Leads to 14.6% Failures.

We deliberately set a low max tokens parameter (4k) but didn't mention it in the eval criteria. AgentLens identified truncation as a major failure mode, determined it was statistically significant, and generated a visualization showing the pattern without being told to look for it.
Insight 3: Performance varies significantly by repository.

Some repositories are universally easier (marshmallow-code, pylint-dev score green across all dimensions), while others are universally harder (pyvista, sqlfluff score red across the board). AgentLens identified that repository-specific factors were confounding results, decided a heatmap was the right way to surface it, and flagged the pattern. This helps separate "my agent is bad" from "this task is hard."
AgentLens ran autonomously: it reviewed all 225 samples, identified patterns worth surfacing, and generated a full dashboard for you to explore. None of this was pre-specified. MetricAgents evaluated each trace, InsightMiners found the patterns, SynthesisAgents decided what mattered and how to visualize it.
Validating Sample-Level Accuracy
We want to empirically validate that AgentLens works. But the kind of evaluation we're describing, surfacing systemic patterns across a corpus and discovering failure modes you didn't anticipate, is a new paradigm. Rigorous benchmarks for corpus-level evaluation don't yet exist.
So we start where we can: validating that our MetricAgents produce accurate assessments at the sample level. If trace-level scoring isn't reliable, nothing built on top of it will be either.
How we evaluated. We used the precise instruction-following split of RewardBench2, which measures whether an evaluation metric agrees with human judgments of instruction following. We ran our suite of MetricAgents on each sample, producing independent evaluations with rationales and structured verdicts. These were then passed to an aggregation agent, which synthesizes the evidence to produce a final preference judgment.
| Precise-IF Accuracy % | |
|---|---|
| Contextual AI LMUnit | 54.4 |
| Dynamic Eval Agent | 52.4 |
| AgentLens’ MetricAgents | 60.7 |
Our dynamic multi-agent setup outperforms both LMUnit—one of the top models on the RewardBench2 leaderboard—and a single dynamic agent tasked with judging preference directly.
The results give us confidence that the foundation is solid. But we believe the real value of AgentLens lies beyond what sample-level benchmarks can measure: in the patterns that emerge when you evaluate thousands of traces together. We're excited to demonstrate this more rigorously as the field develops better ways to evaluate corpus-level insights.
An Eval System That Learns
Evaluation criteria shouldn't be static. Your product changes, your users surprise you, and what mattered last month might not matter next month. Often, you're still figuring out what "good" looks like as you go. AgentLens is designed to evolve alongside your needs.
The way this works: you provide natural language feedback at any level, and the system updates accordingly. Flag a sample as incorrectly scored. Ask to explore a correlation. Point out a pattern you want to track. The system reasons about your feedback, updates the Eval Spec, and incorporates your input into future runs.
Here's what this looks like in practice.
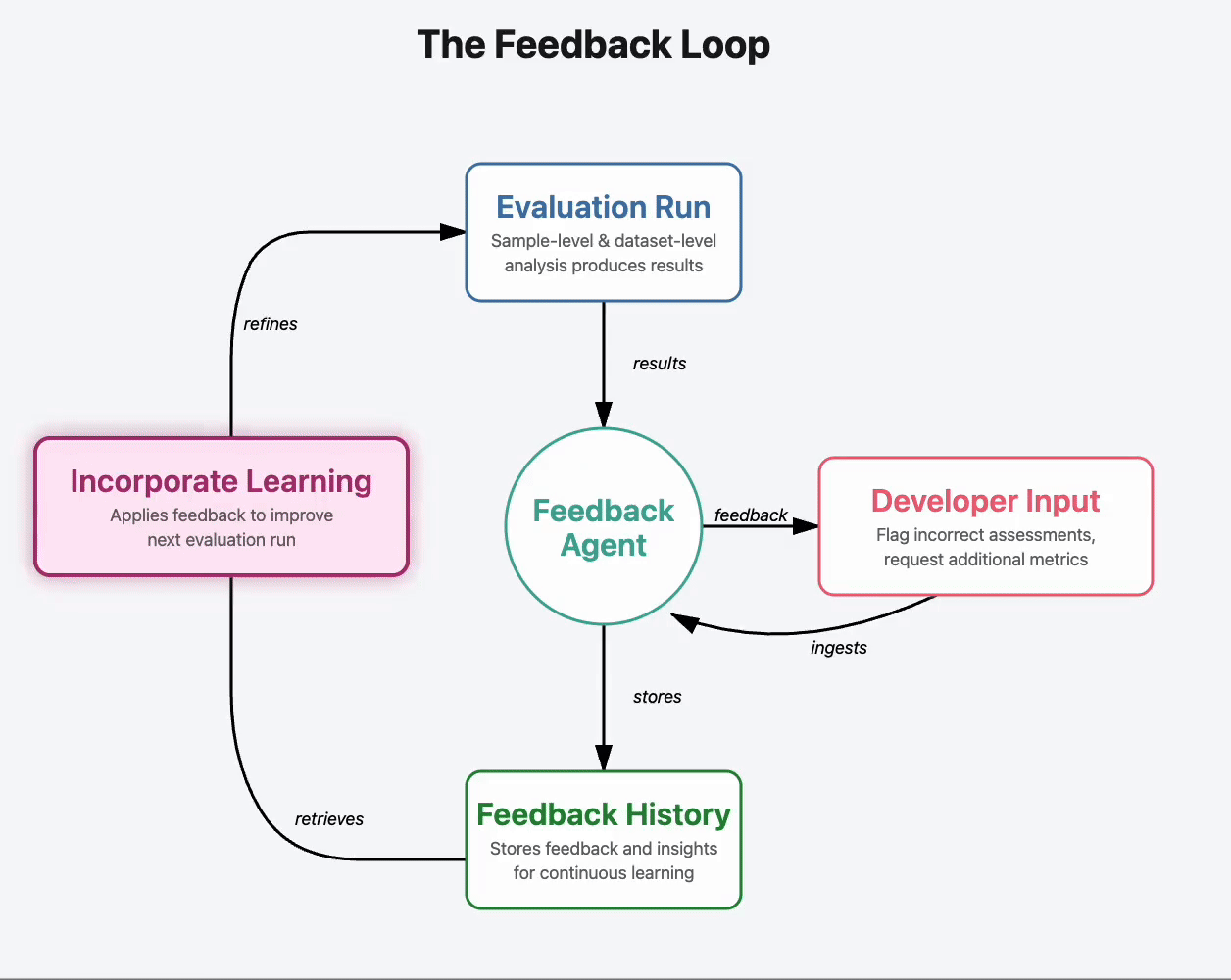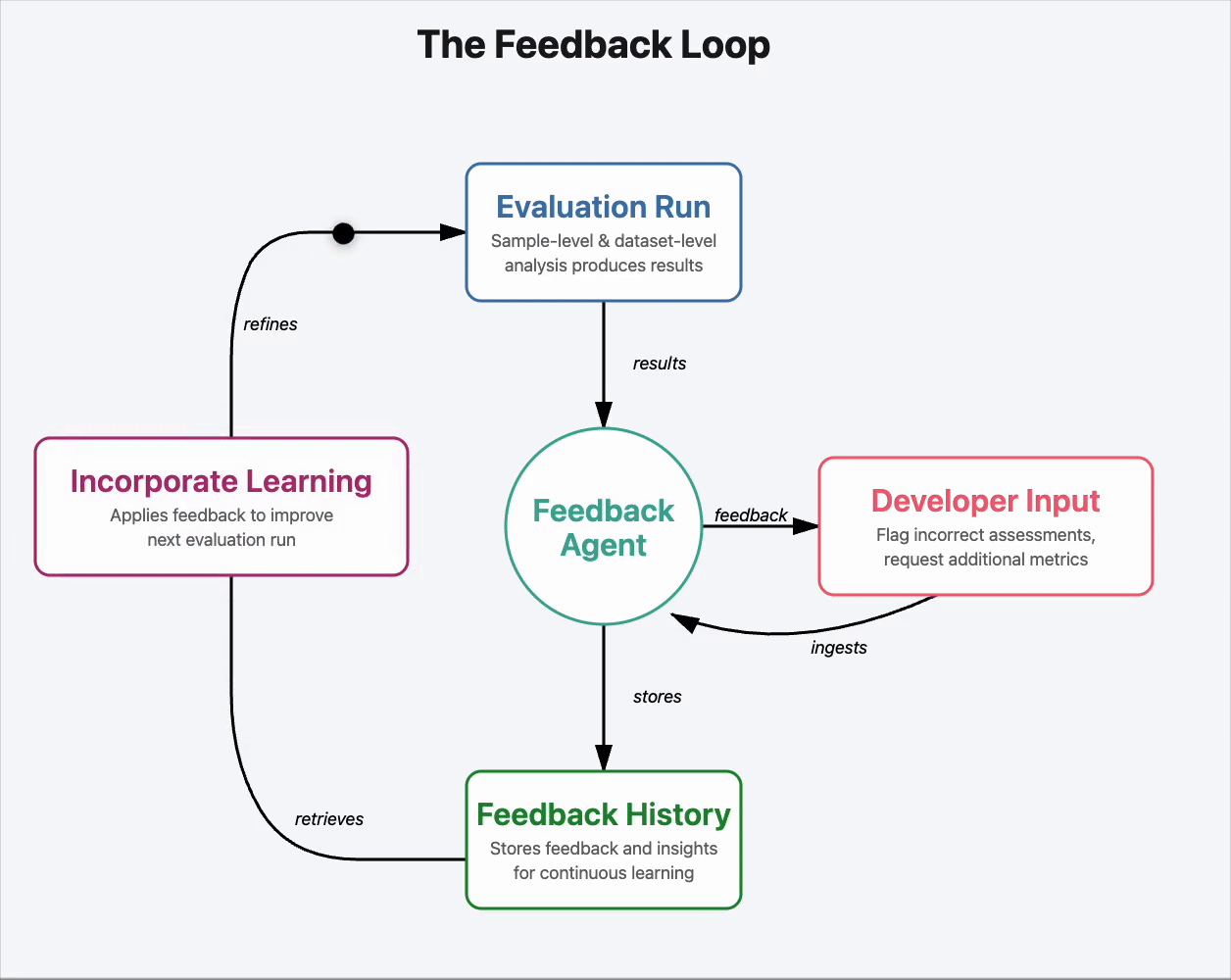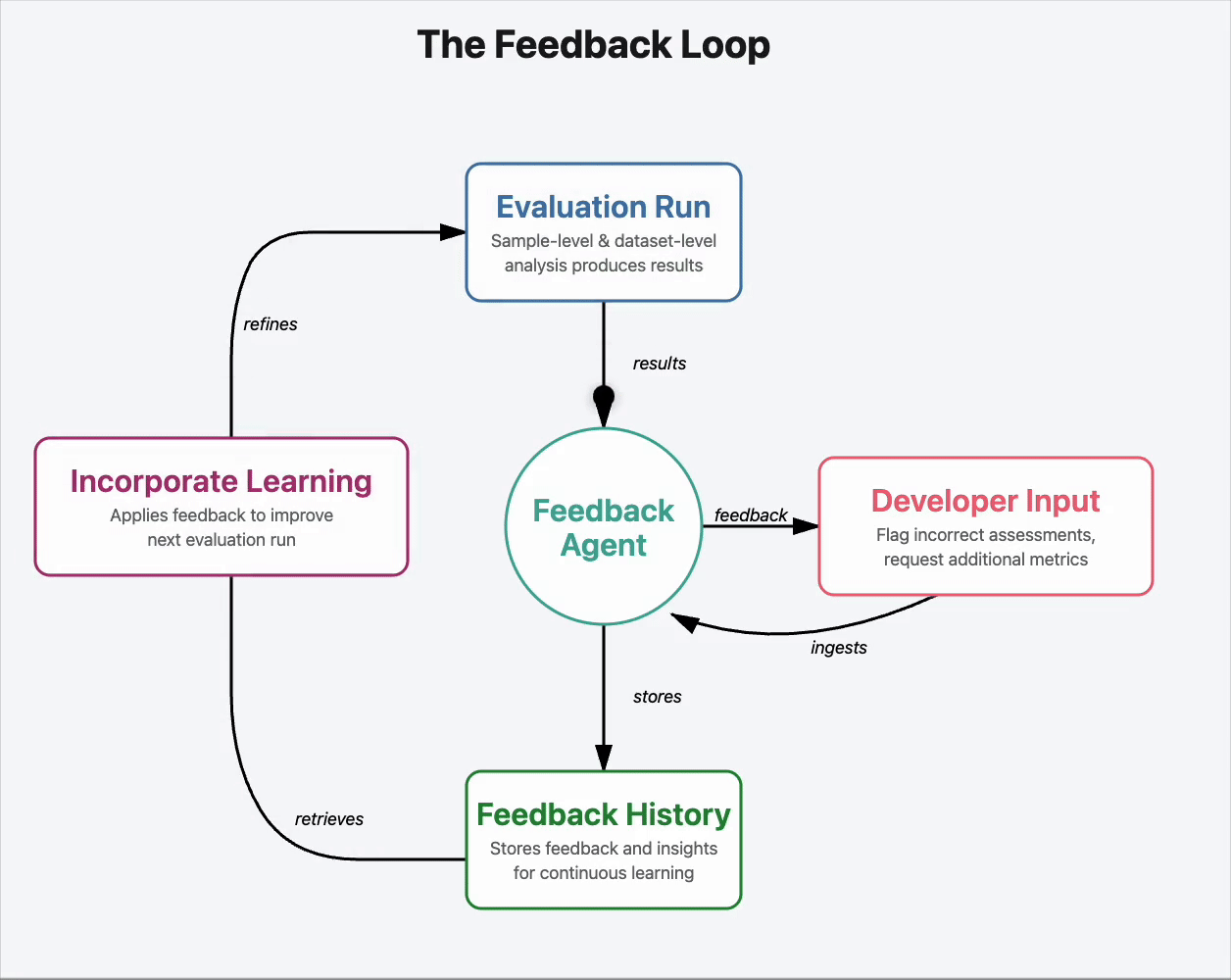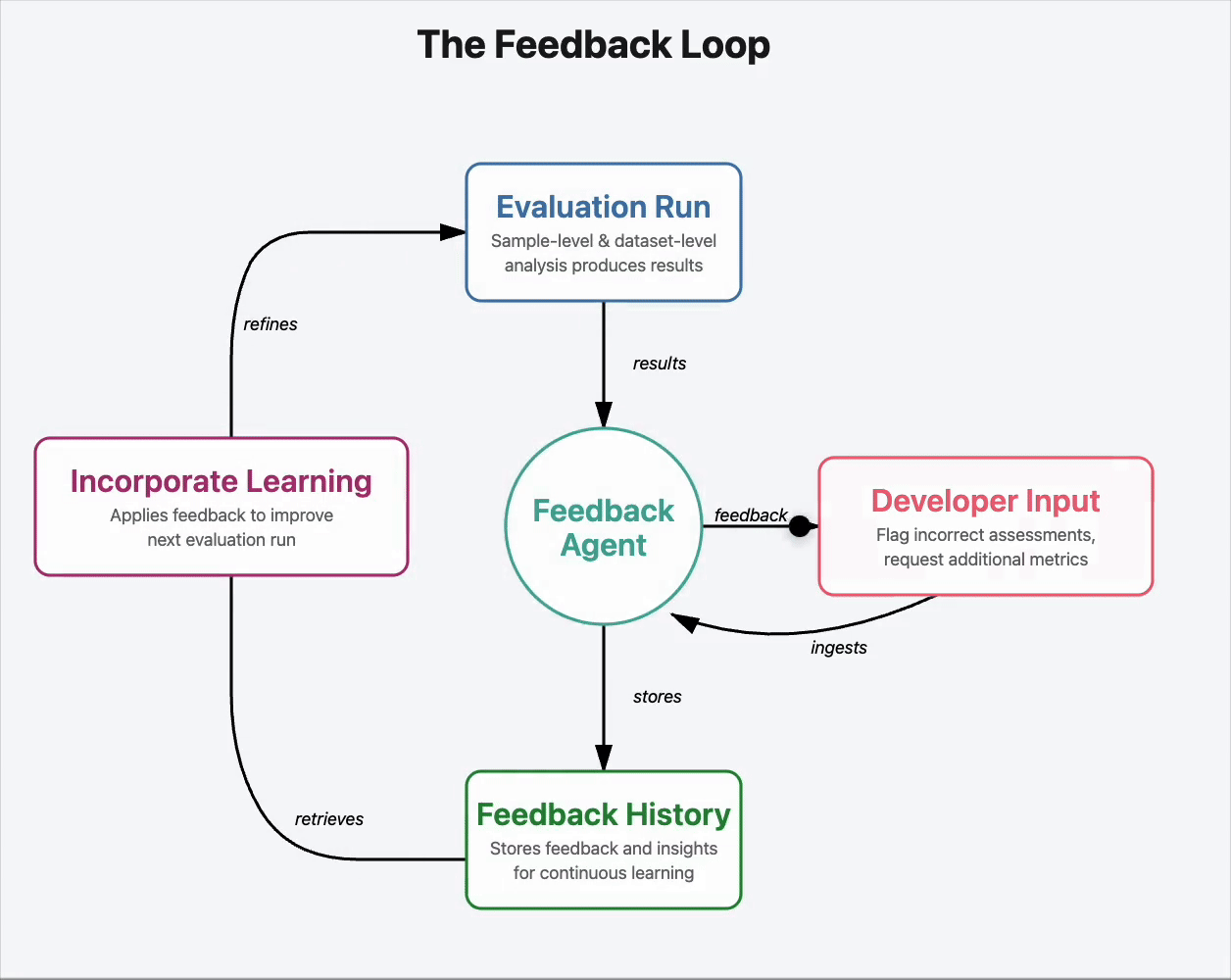
You're evaluating your agent's ability to generate code. The system produces an initial dashboard with overall performance metrics, broken down by repository category. You notice something: there seems to be a correlation between holistic code quality and syntactic correctness.

You provide feedback: "Help me understand better the relationship between syntactic correctness and diff quality."
The system generates a scatter plot to visualize the relationship. Now you want to dig deeper.

You provide a second round of feedback: "Show me examples where syntactic correctness is high but the patch still fails. What's going wrong?"
The system performs targeted clustering on this subset of traces and surfaces the patterns.

Each iteration took less than 5 minutes. And the system incorporates these preferences into all future evaluation runs, transforming from a generic tool into one that understands your specific needs.
Conclusion
Static benchmarks and LLM-as-judge got us this far, but they weren't built for the way AI products actually evolve. They measure, but they don't help you systematically improve. And they can't surface the large-scale patterns that are invisible in trace-by-trace review.
AgentLens is a different approach: an evaluation system that surfaces deeper insights, learns what matters for your product, and gives you a real path to hill-climbing agent performance. It puts control directly in the hands of the people who understand their products best.
We believe this is a crucial research direction. ML engineers and researchers are often shooting in the dark, iterating without clear signal on what's working. Agentic evaluation with continuous learning is the most promising path forward, and for enterprises shipping AI products, it's table stakes.
This is a paradigm shift from static benchmarking to dynamic, developer-driven evaluation. At Contextual AI, we'll keep pushing on this frontier, helping customers understand and improve their agents along the way. The future of evaluation is agentic.


