
Most natural language problems can be reduced to one of two things: generation, or representation. We either want to generate new sequences of text, or we want to represent text in such a way that we can retrieve it, cluster it, and classify it.
Modern machine learning pipelines, however, often involve components of both types. A good example is retrieval augmented generation (RAG), where representations (i.e., embeddings) are used for retrieval, the results of which are then used to augment a generative model.
Embedding models tend to be trained with a contrastive loss, while generative language models are trained causally, or autoregressively. Thanks to instruction finetuning, however, generative models are getting increasingly good at discriminative tasks. A natural question to ask is, then, what if we used instruction learning to train one single model to be good at both generation and representation?
There are three main reasons for why this is a good idea. First of all, it is expensive to train separate models. Often, embedding models are still initialized from generative language models for this reason. Second, learning both tasks simultaneously might enable the model to generalize better, because it gets an even richer training signal. Lastly, if we used the same model for both generation and representation, as we will show here, we can do RAG much more efficiently.
Training with GRIT
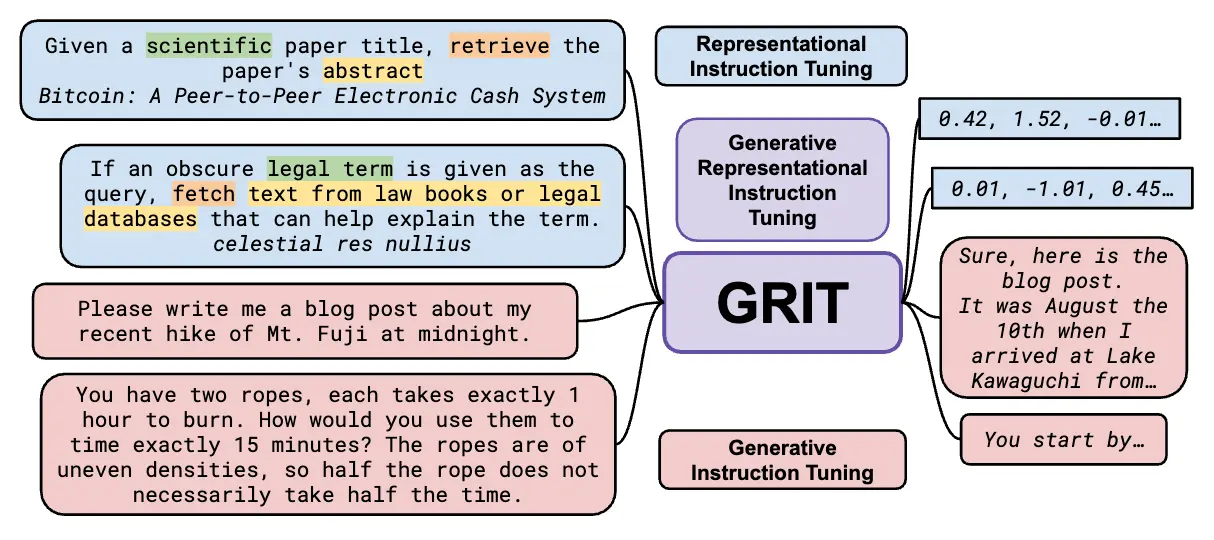
We introduce GRIT (Generative Representational Instruction Tuning), a novel technique for using instructions to train language models to be good at both representation and generation. In this new paradigm, the model simply learns to follow instructions along the lines of “represent this piece of text so that a doctor can find relevant information to make the right decision”. We jointly optimize the same core model with both a contrastive and a causal loss during instruction tuning. For more details, please see our paper.
Using this approach, we trained a new model that sets a new state of the art on the MTEB benchmark for representational quality. The same model also achieves at-or-near in-class state-of-the-art performance on generative benchmarks:
Faster RAG
Most modern LLM deployments, especially in production settings, tend to follow the RAG paradigm, where a retriever and language model work together to solve the problem. Traditional RAG is computationally far from optimal, because the query and the documents have to be encoded twice: once by the embedding model for retrieval, and once by the language model as context. If we had the same model, we could cache (i.e., save for later) parts of the network during retrieval, and re-use them during generation.
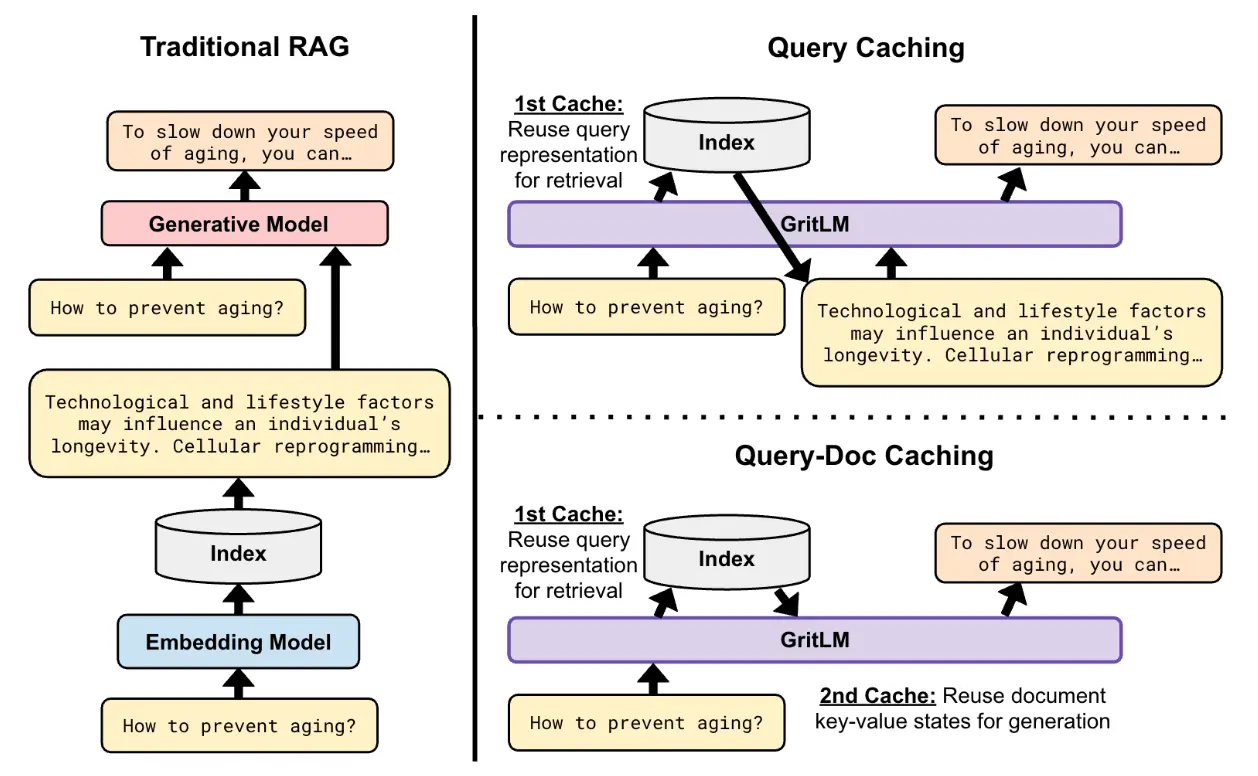
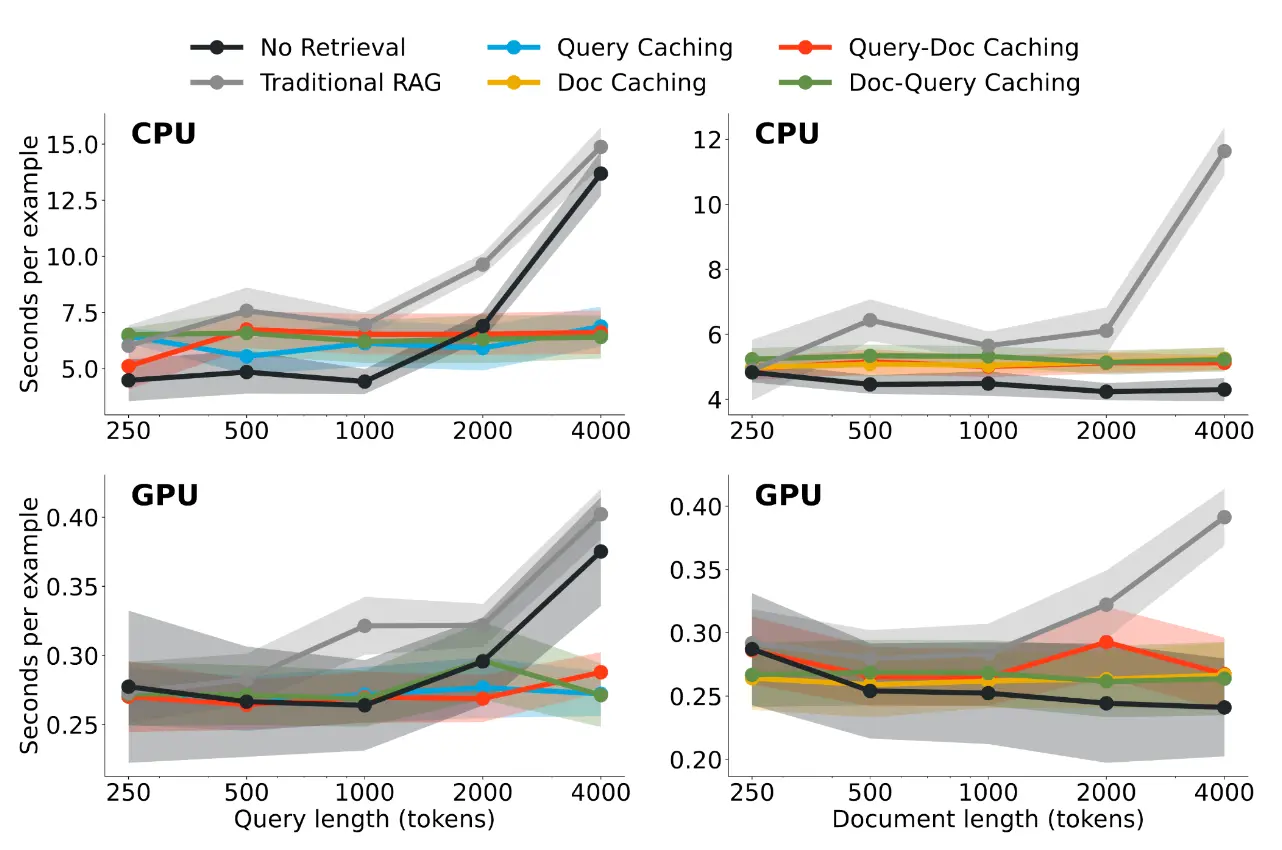
There are different ways to approach this: you can either cache the query, the documents, or both, and in different orders – see the paper for more details. Our best method leads to more than 60% efficiency gains over naive RAG, and is actually quite close to the time it would have taken to directly generate without retrieving at all:
Opening up future research
Aside from getting state-of-the-art results on important benchmarks and leading to substantial efficiency gains for RAG, GRIT also opens up other intriguing possibilities: to what extent can instructions be contextualized for retrieval for specific domains, for example; or can we do few-shot retrieval where we put demonstrations in-context? We encourage you to read the paper for more information and insights.
At Contextual AI we are strong supporters of open source and open science: all models are available here. We thank our friends at the University of Hong Kong and Microsoft for a wonderful collaboration.