User feedback and annotation is now built into the Contextual AI Platform



AI teams can now audit and improve agent performance entirely within the Contextual AI platform. Collect, categorize, and visualize human feedback to resolve quality concerns around accuracy and use-case specialization —all without juggling separate spreadsheets, annotation tools, and dashboards.
Why human evaluation breaks down
After an agent is initially set up, the challenge of optimizing the AI workflow for production begins. For many of our customers, this “hill-climbing” to deliver a production-quality AI agent often takes the most effort. These processes start out being highly iterative and manual, and not having the right tooling can add cognitive load through excessive context switching. Many teams struggle with human evaluation because:
- Manual reviews are time-consuming: Annotators spend hours recording user feedback and categorizing issues in spreadsheets.
- Fragmented tools break workflows: Scores, outputs, and logs live in separate systems, forcing constant context-switching to piece together what went wrong.
- Lack of analytics slow improvements: Without automated analytics, teams struggle to identify recurring failures, track resolution progress, or prove improvements over time.
From feedback to resolution in a few steps
The human evaluation workflow in the platform includes tools to:
- Collect: Configure the feedback UI that enables users to grade agent outputs and retrievals
- Categorize: Create custom labels and use them to annotate and organize user feedback
- Investigate: Diagnose the root cause of quality issues by inspecting both agent outputs and the underlying retrieved documents
- Track: Filter feedback, view automated trend visualizations and update issue resolution statuses
“Contextual’s new feedback collection and annotation workflow brings everything into one place—letting us annotate queries, track resolution, and visualize results seamlessly. It’s improved our team’s productivity and reduced the number of tools we need to manage QA.”
— Natasha Gangal - AI Strategy Lead, ShipBob
From user feedback to error resolution
Kick off user evaluation by setting up the feedback workflow in the agent configuration settings. After submitting a query, users are prompted to rate the agent’s response and select optional issue labels. You can customize these labels and make feedback required.
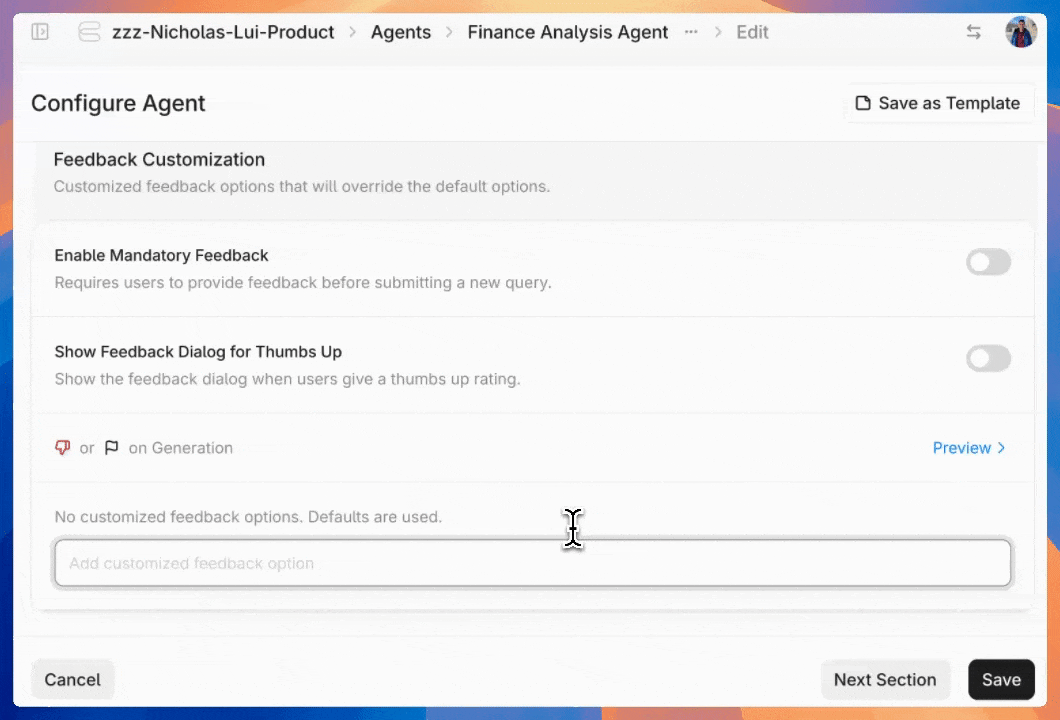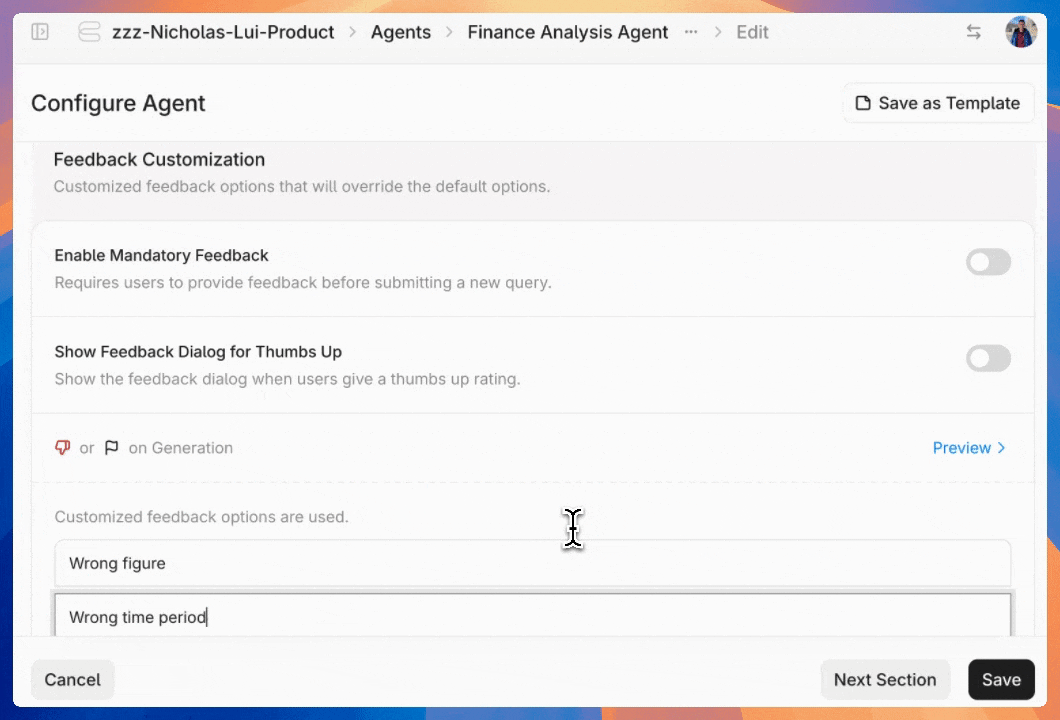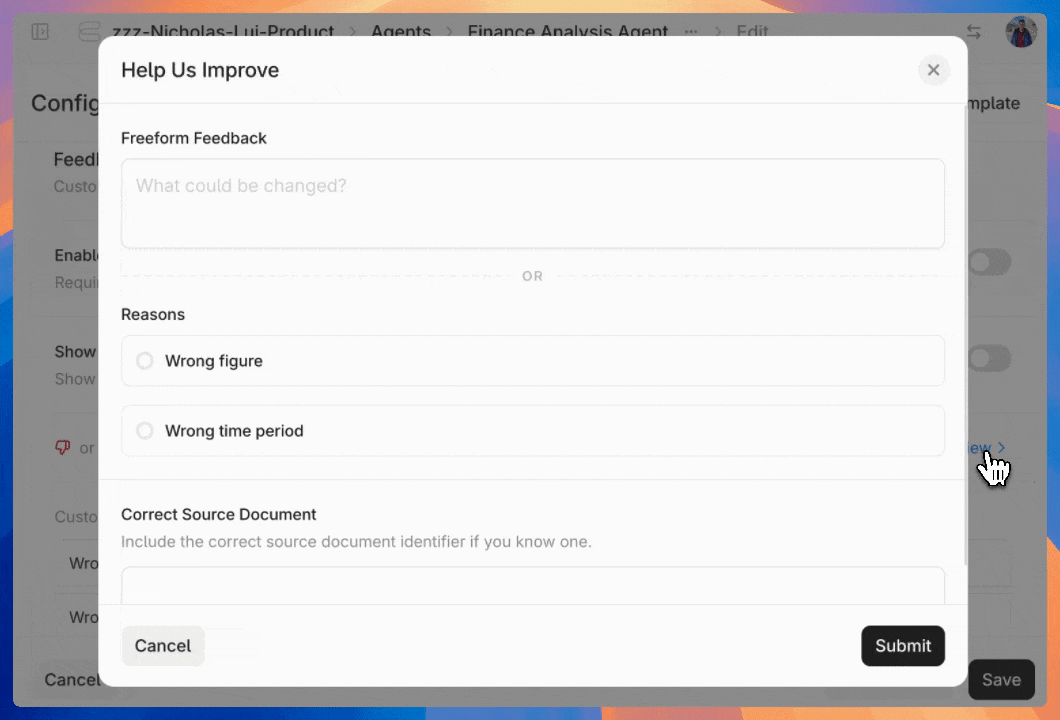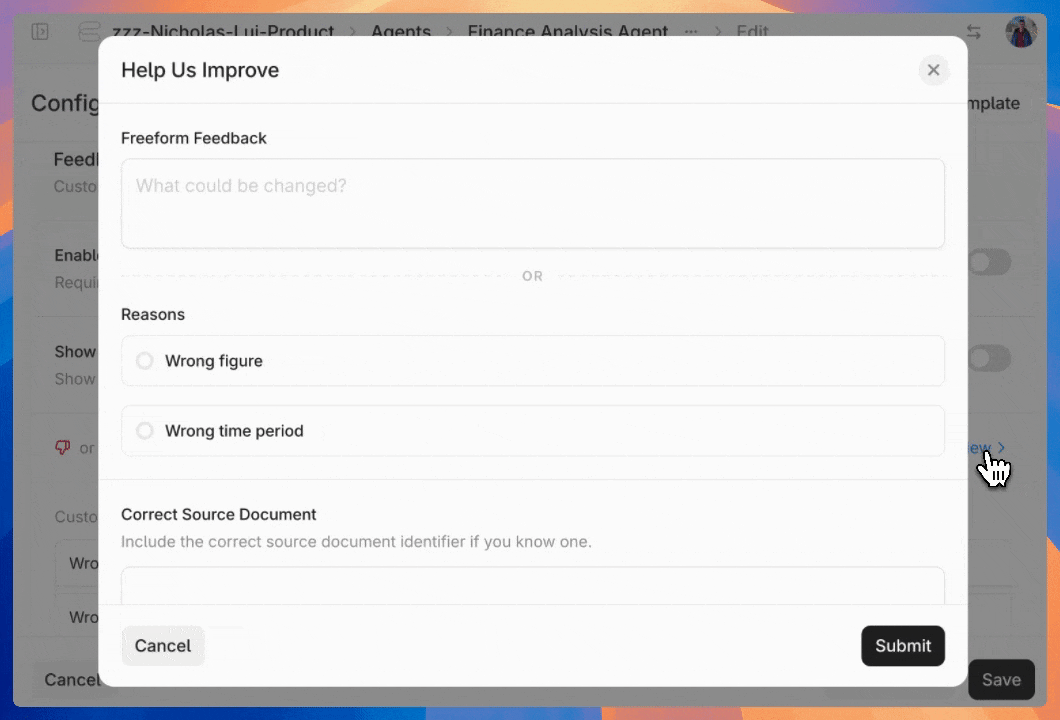
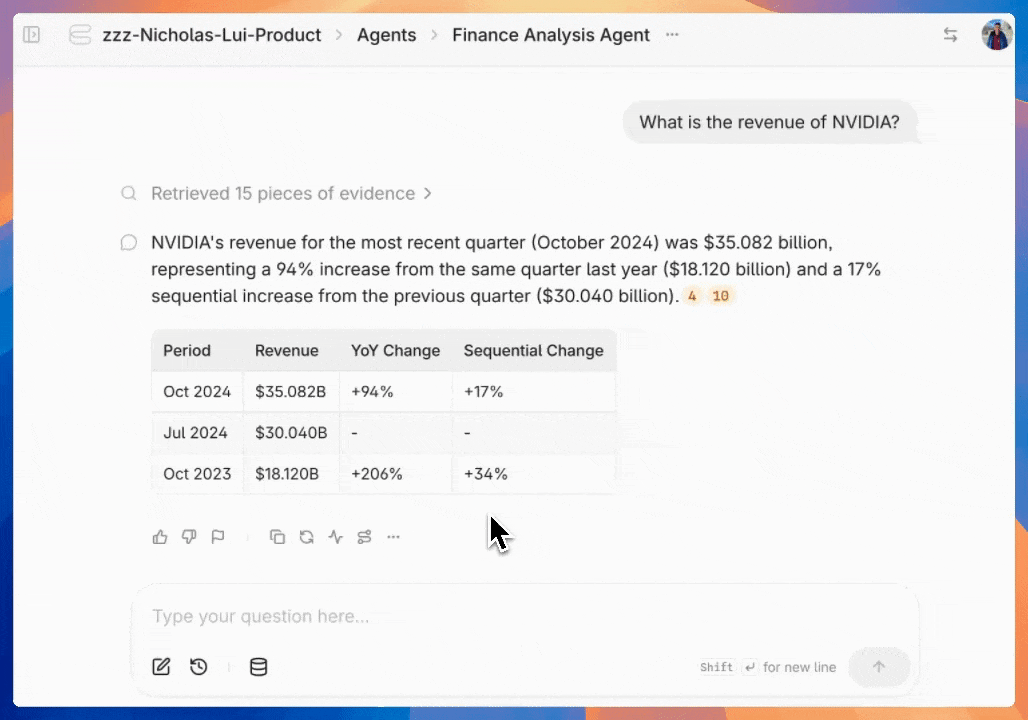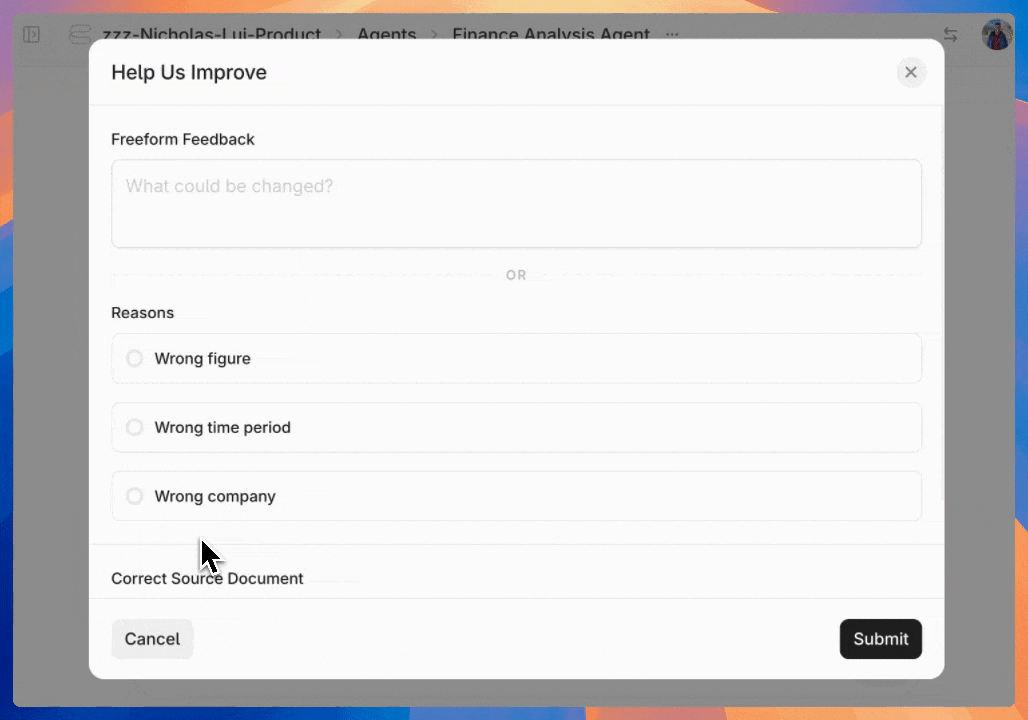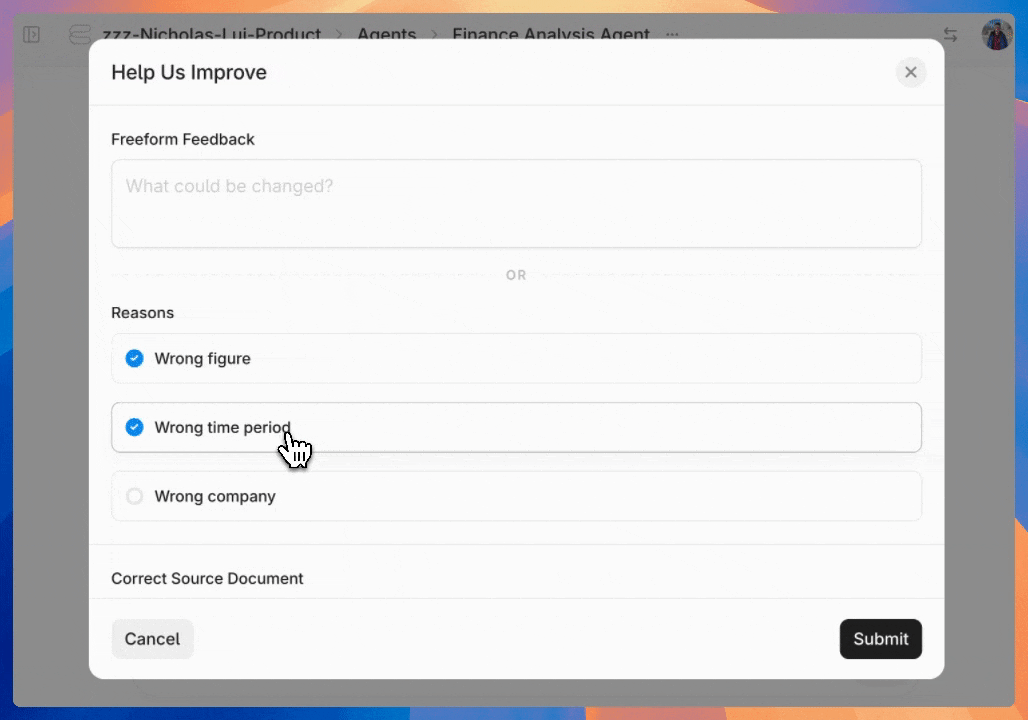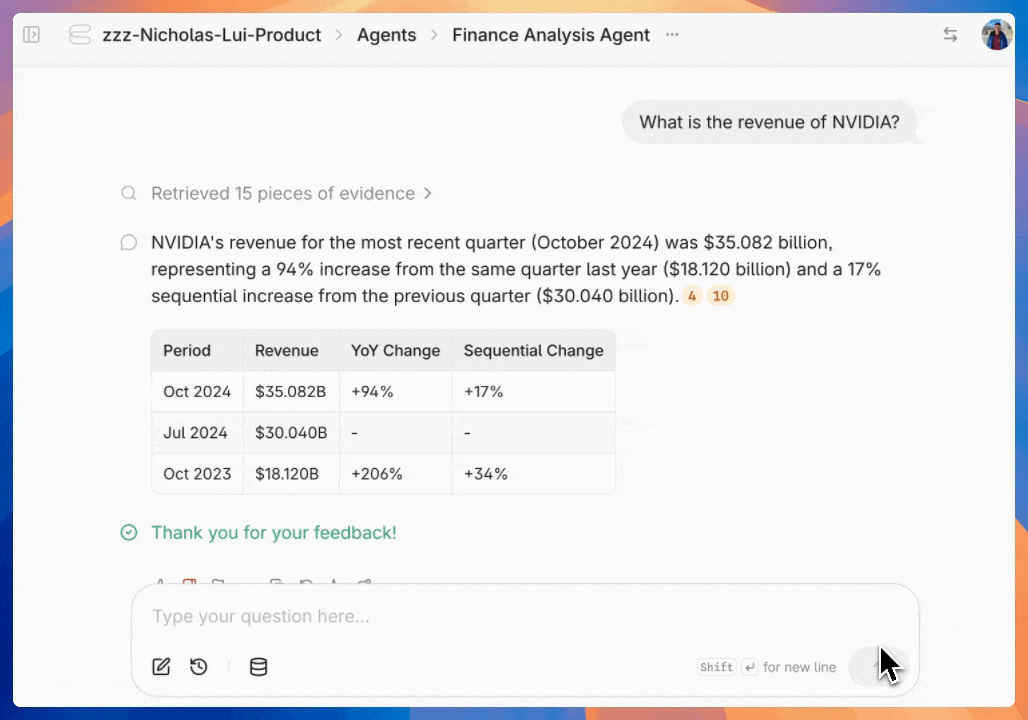
Collecting user feedback
Once you've configured the feedback UI, users can start using intuitive 👍 / 👎 / 🚩 buttons to grade the quality of responses. Negative grades automatically trigger a pop-up for detailed feedback.
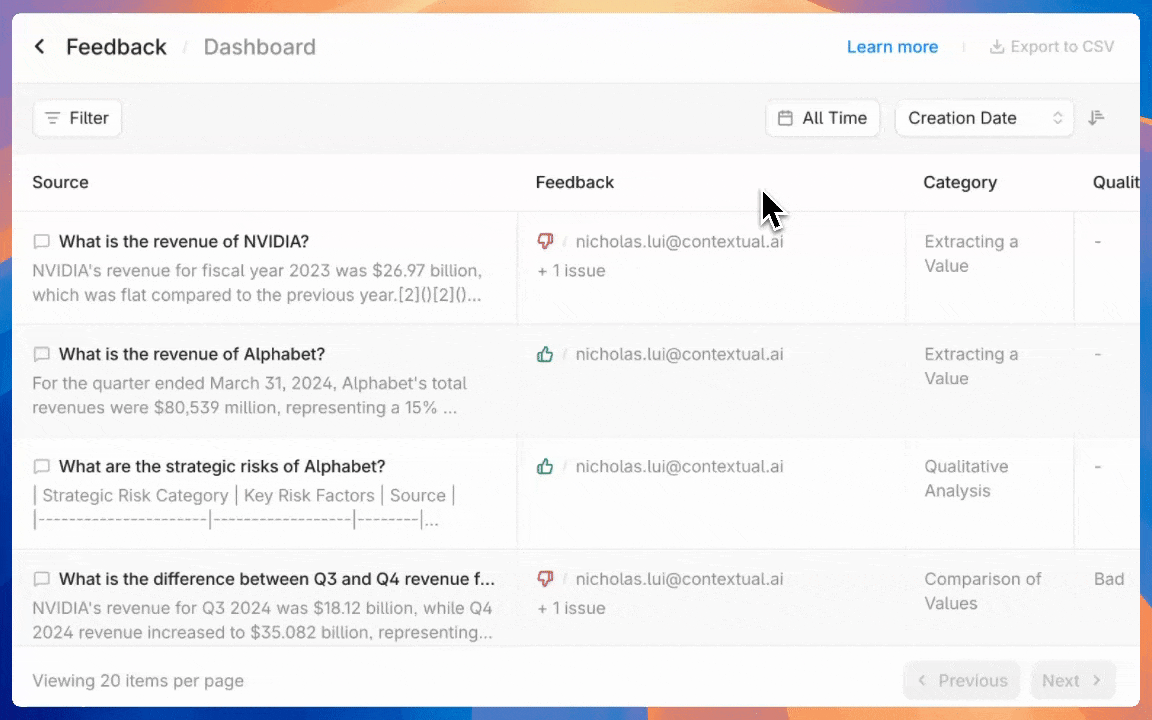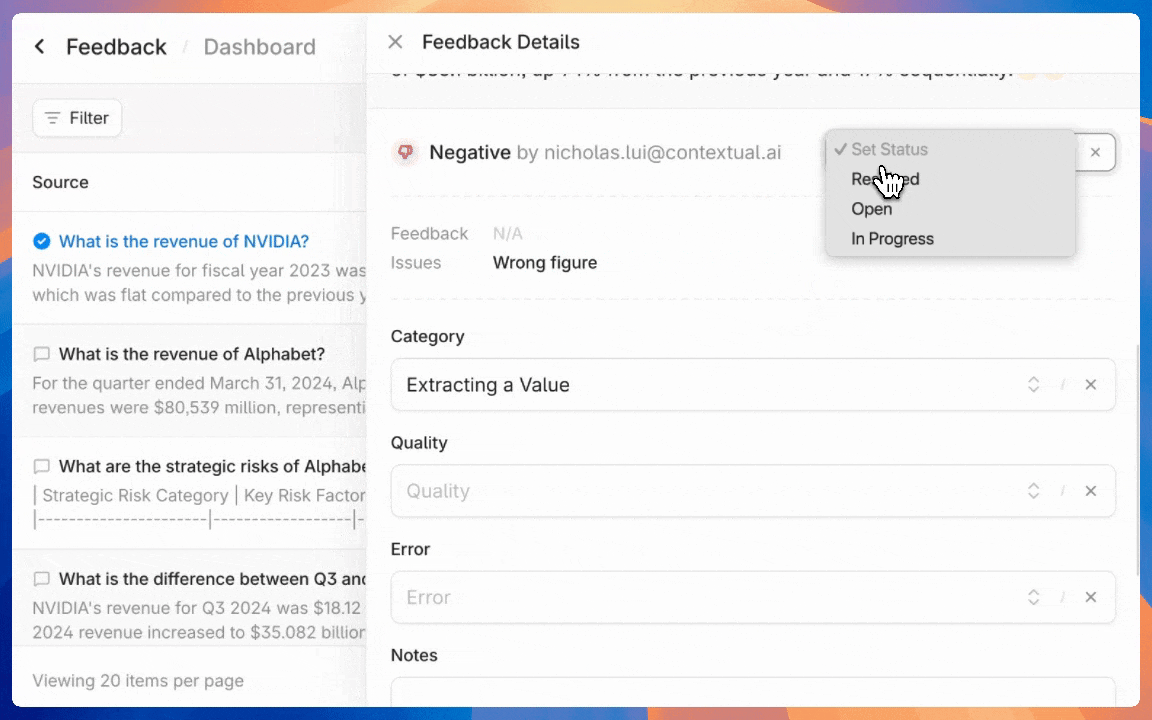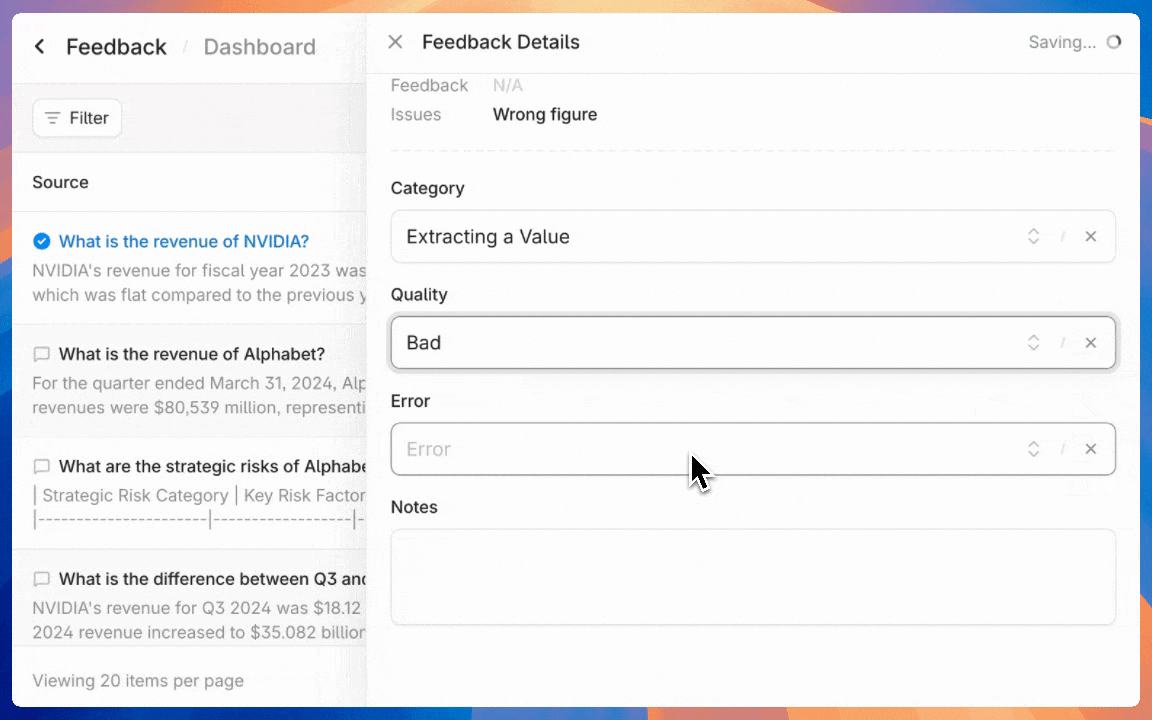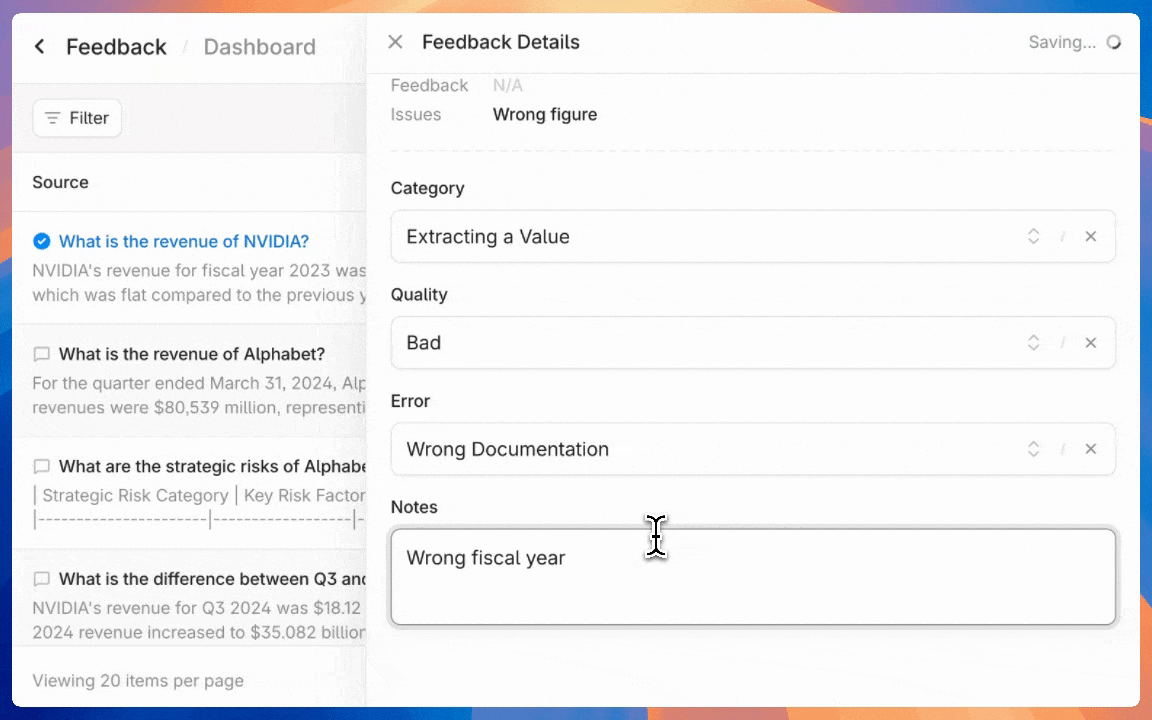
Exploring user feedback
Graded or flagged outputs are immediately populated inside the human evaluation dashboard. You can easily access the dashboard through the agent menu.
Categorizing user feedback
After reviewing initial feedback, developers can set up annotation workflows by creating custom category fields in the agent configuration interface. By default you can create customized categories for queries, errors, response quality, and resolution status.
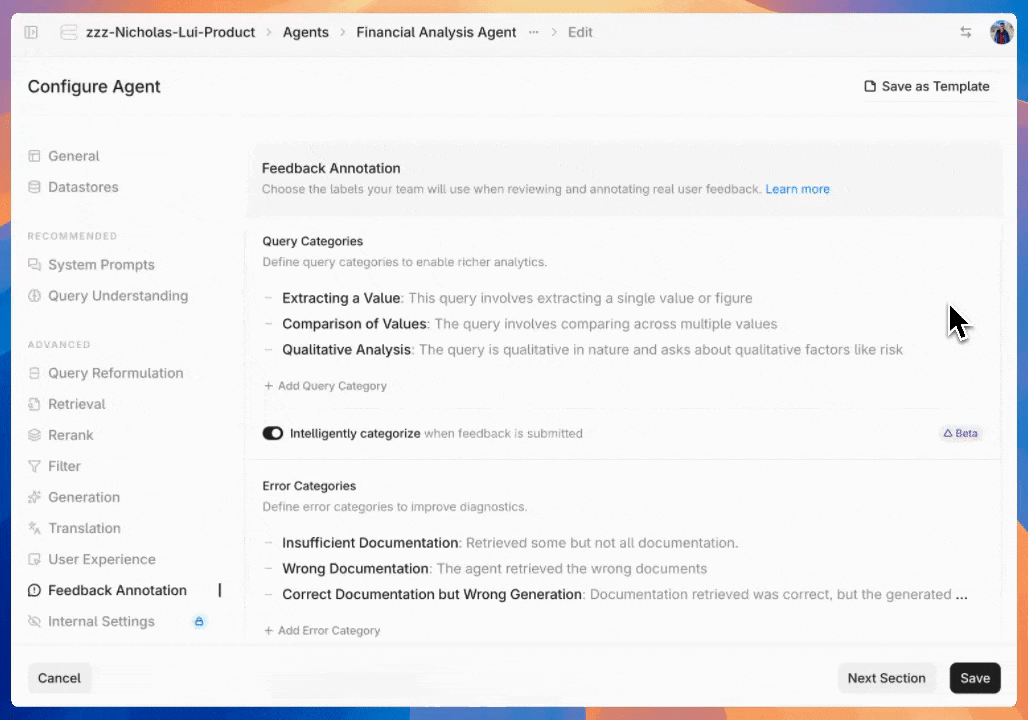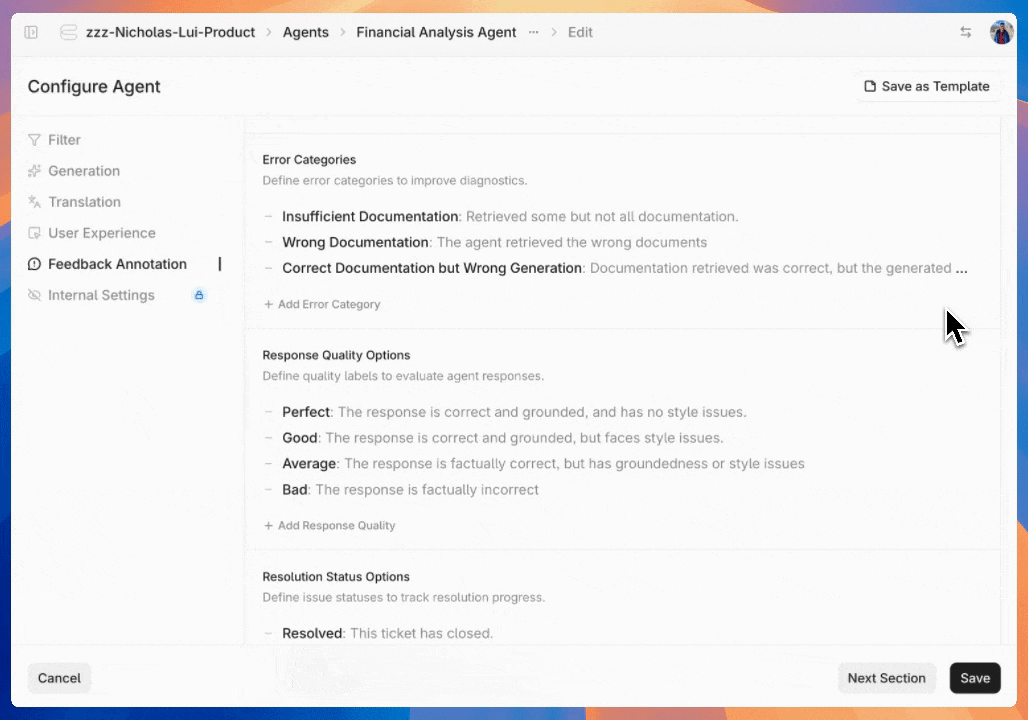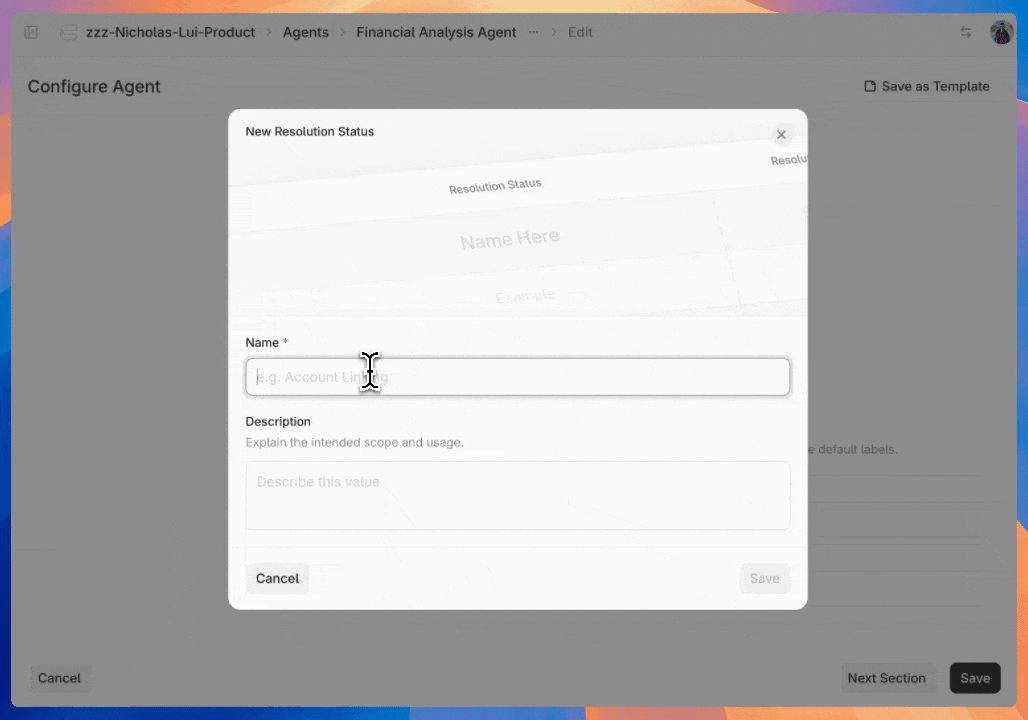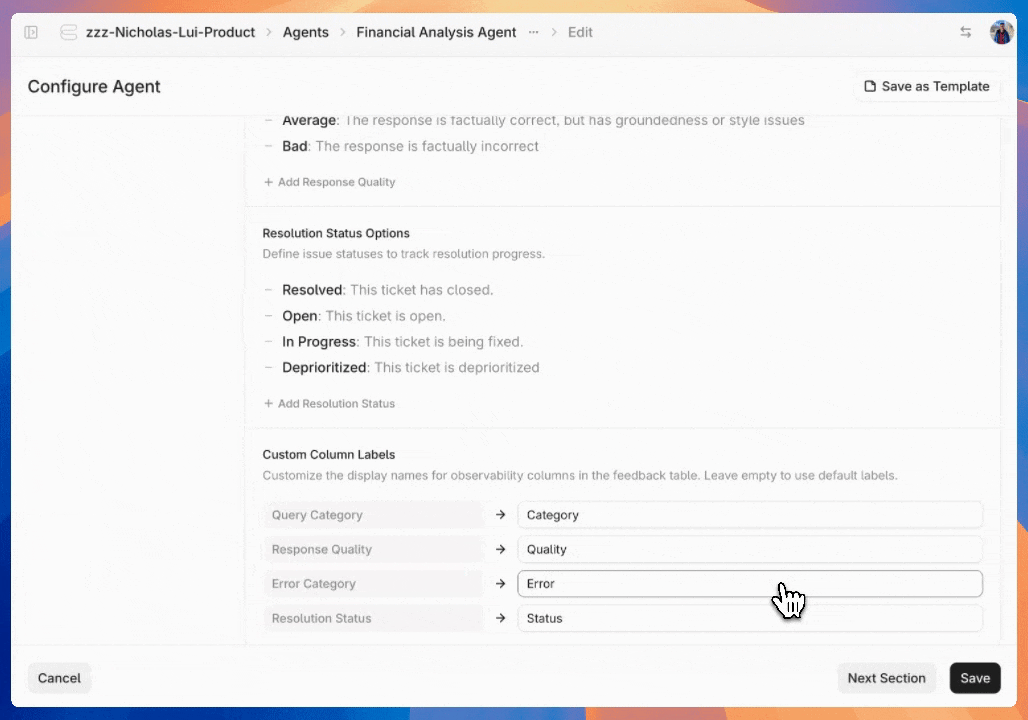
For query categorization, you can use our intelligent prediction system to automatically classify queries into the most relevant category based on your defined labels and descriptions.

If you don't like the default category names, you can change them to whatever makes sense for your team.

Organizing reviewed and flagged outputs is seamless. Developers can annotate each piece of feedback with the previously defined labels.
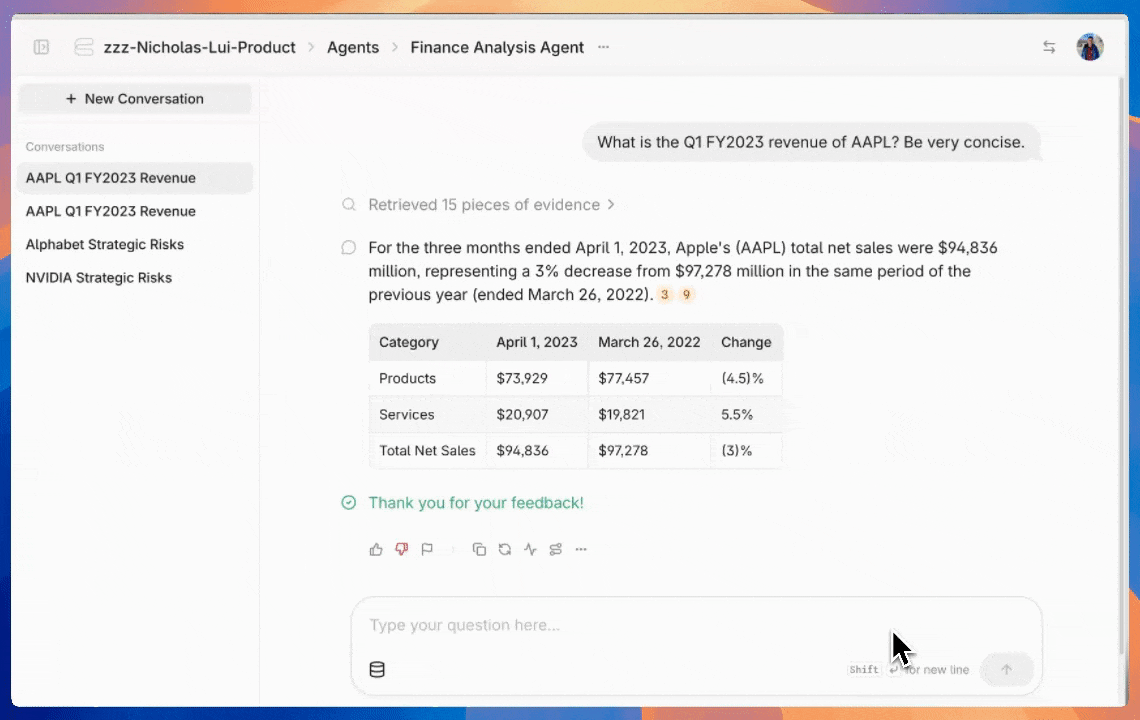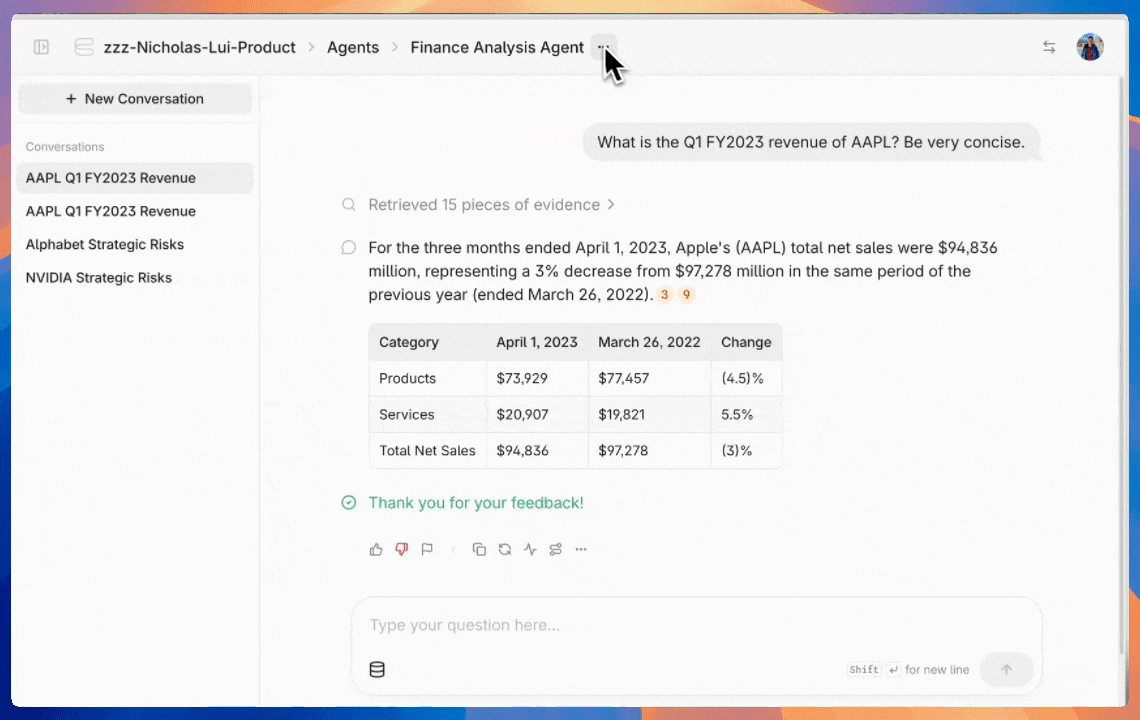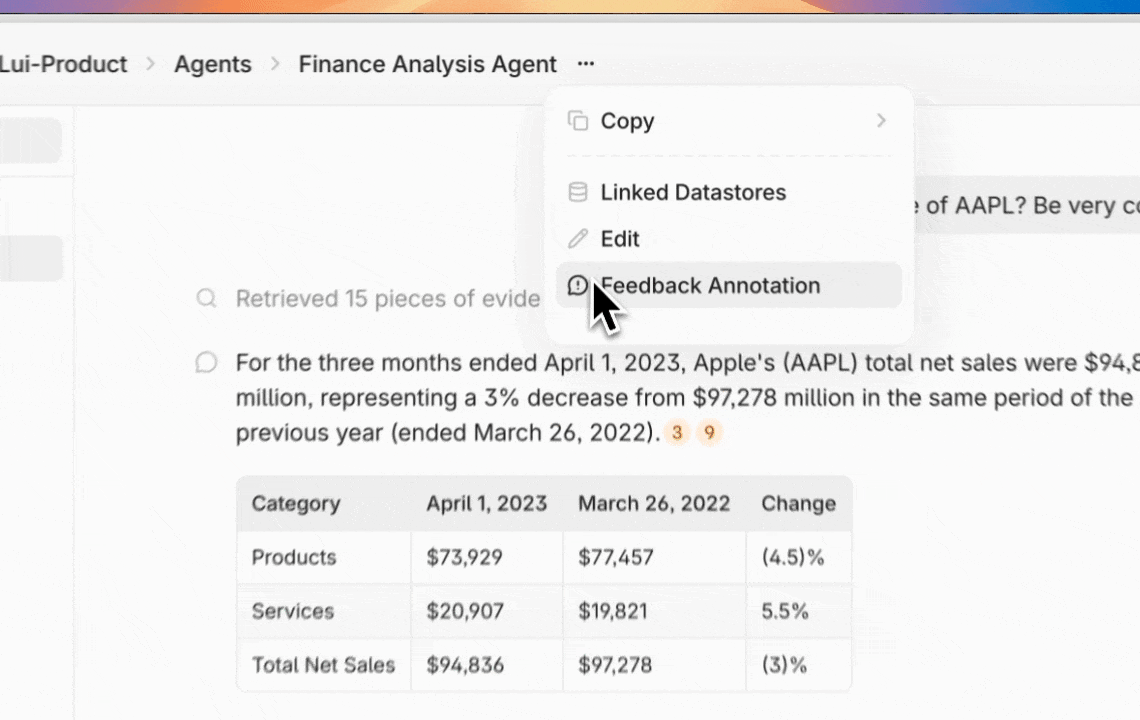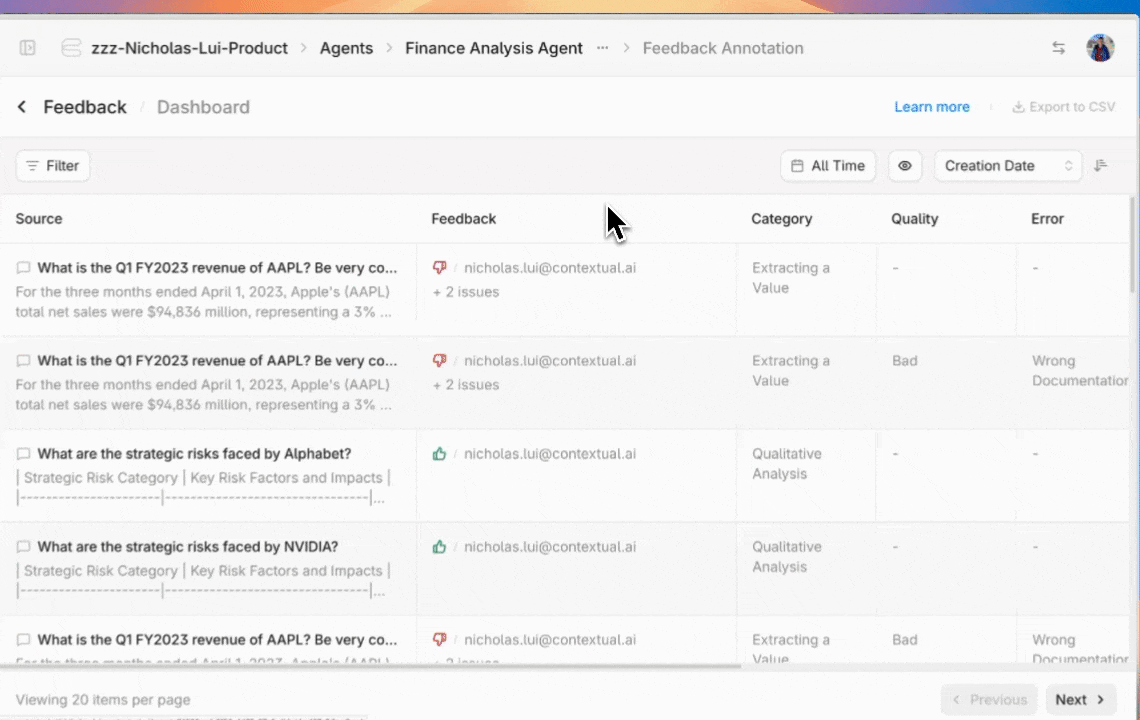
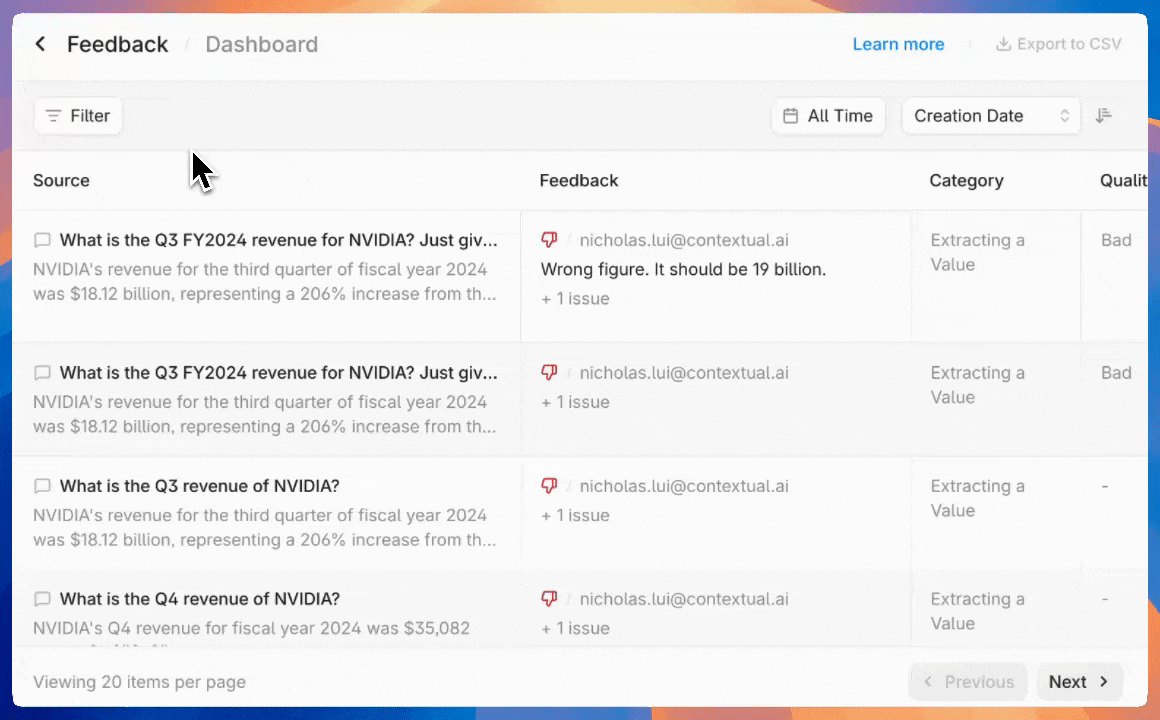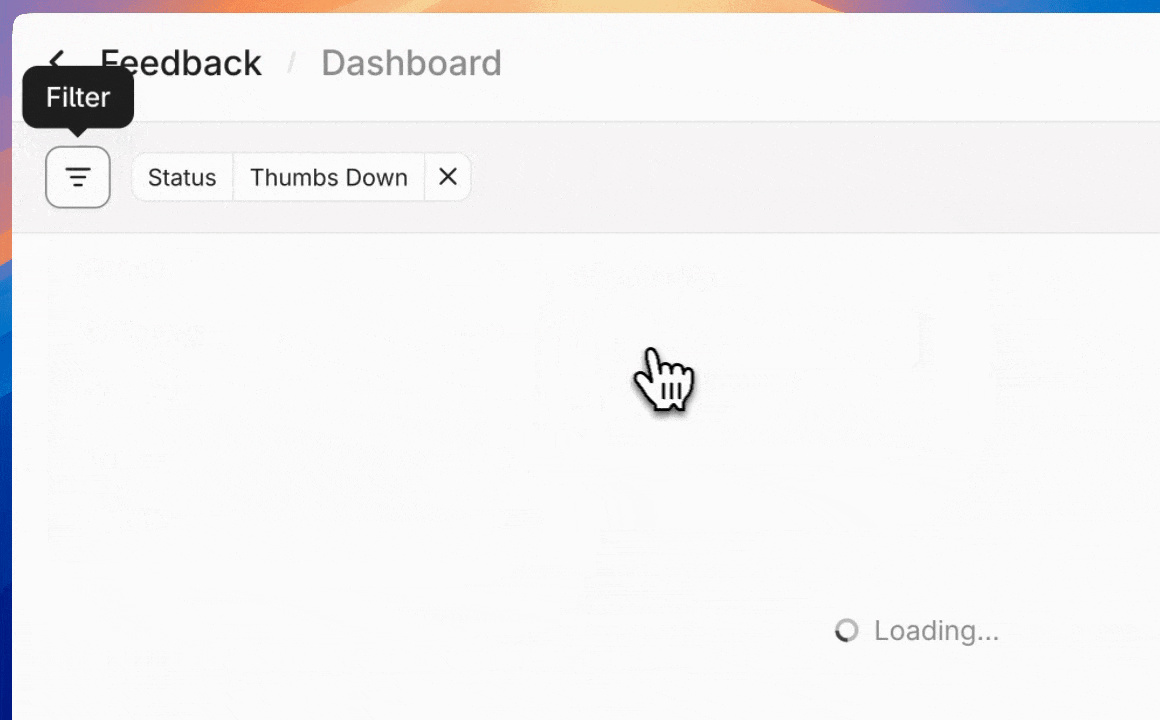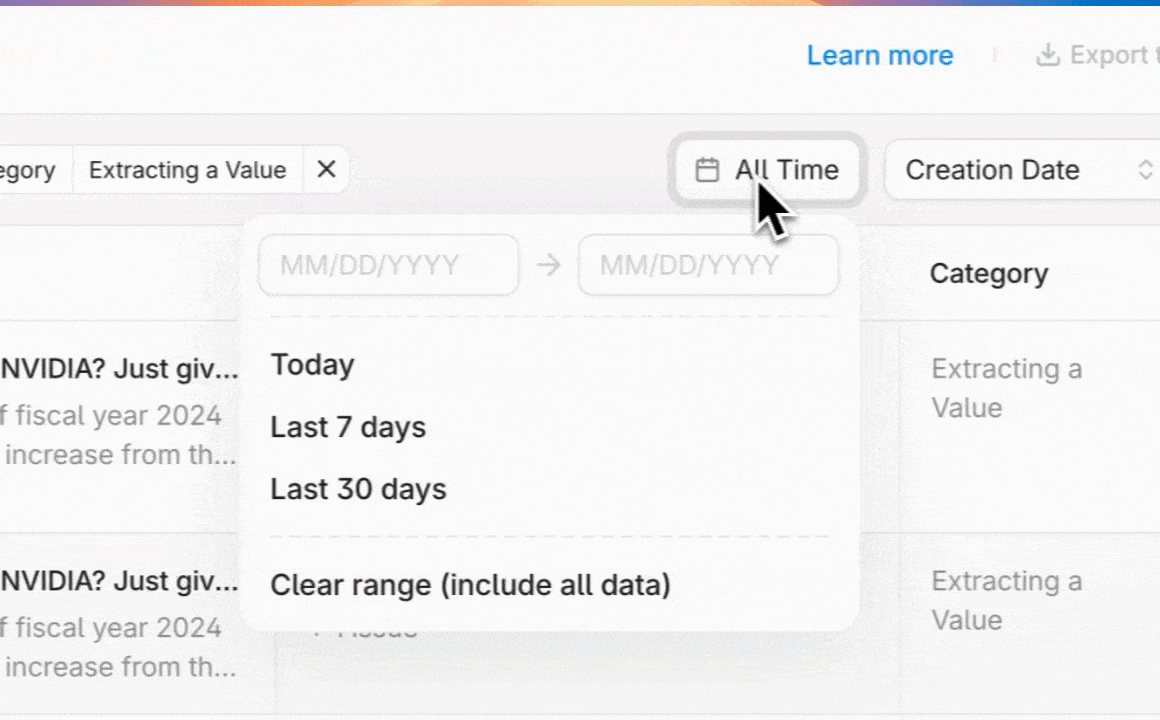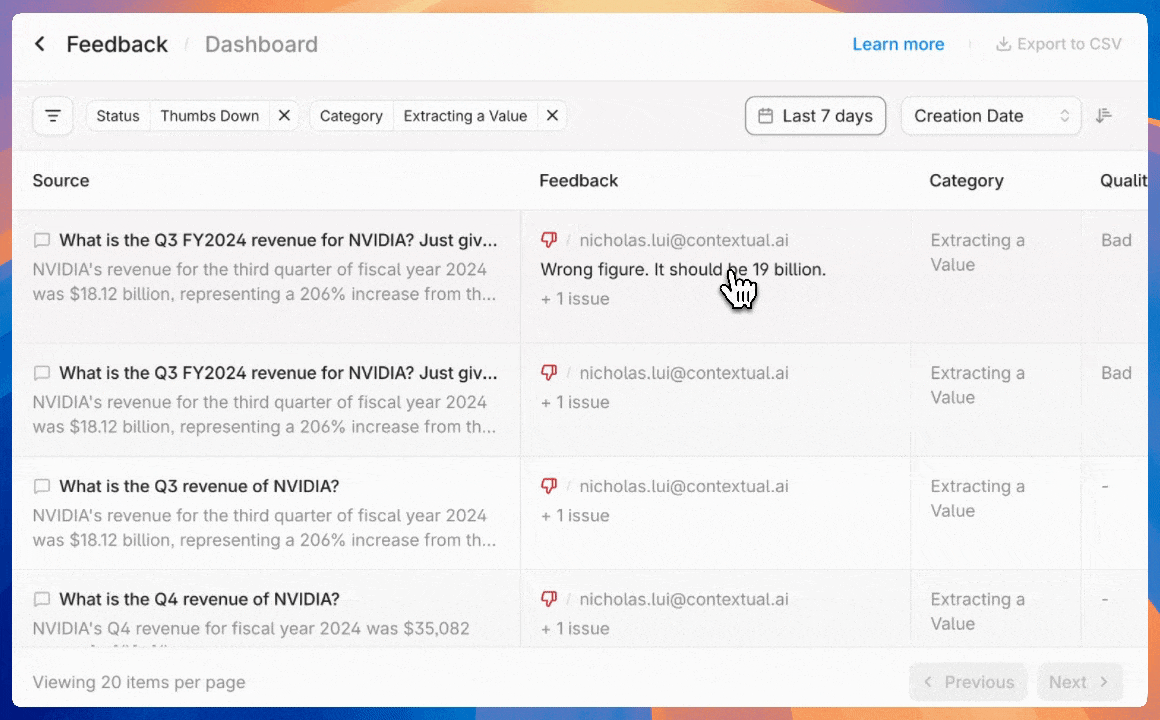
Tracking and resolving quality issues
Manage annotated outputs with granular filtering and status tracking tools. Granular filters can surface outputs that need attention by evaluation criteria, time period, or resolution status.
Get instant root cause analysis by clicking any agent citation to see the prompt, output and source document chunks.
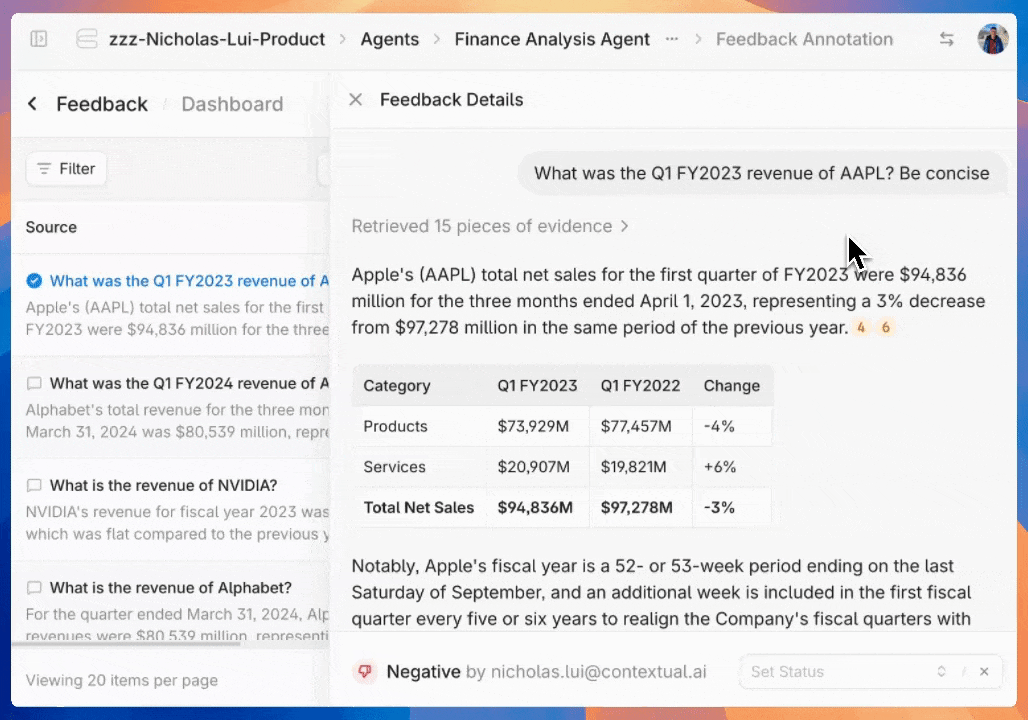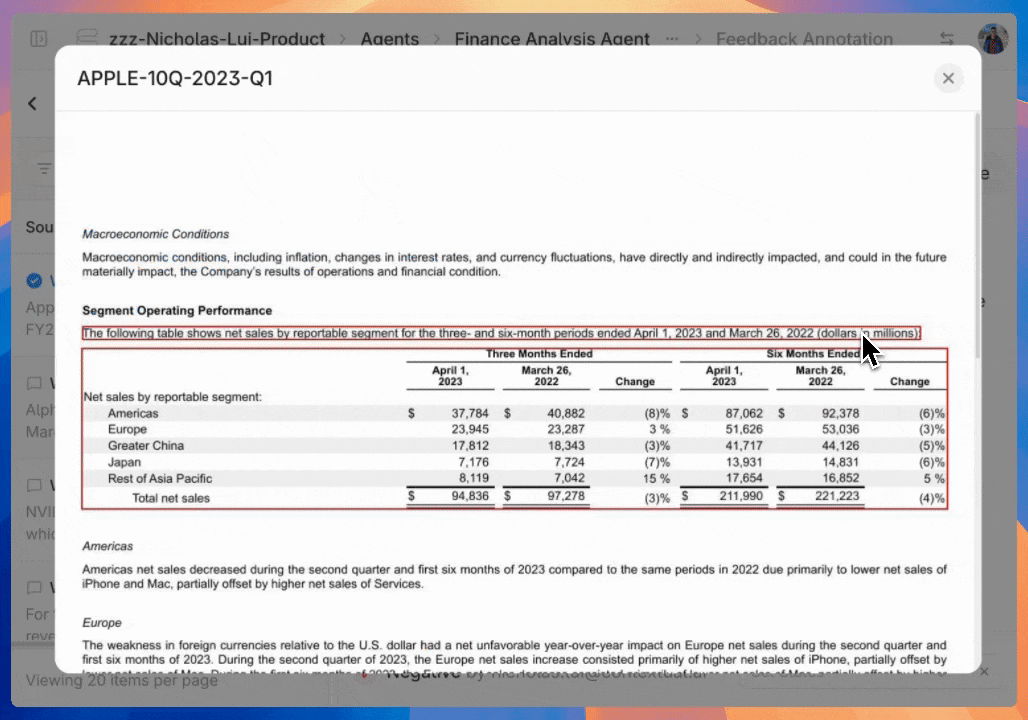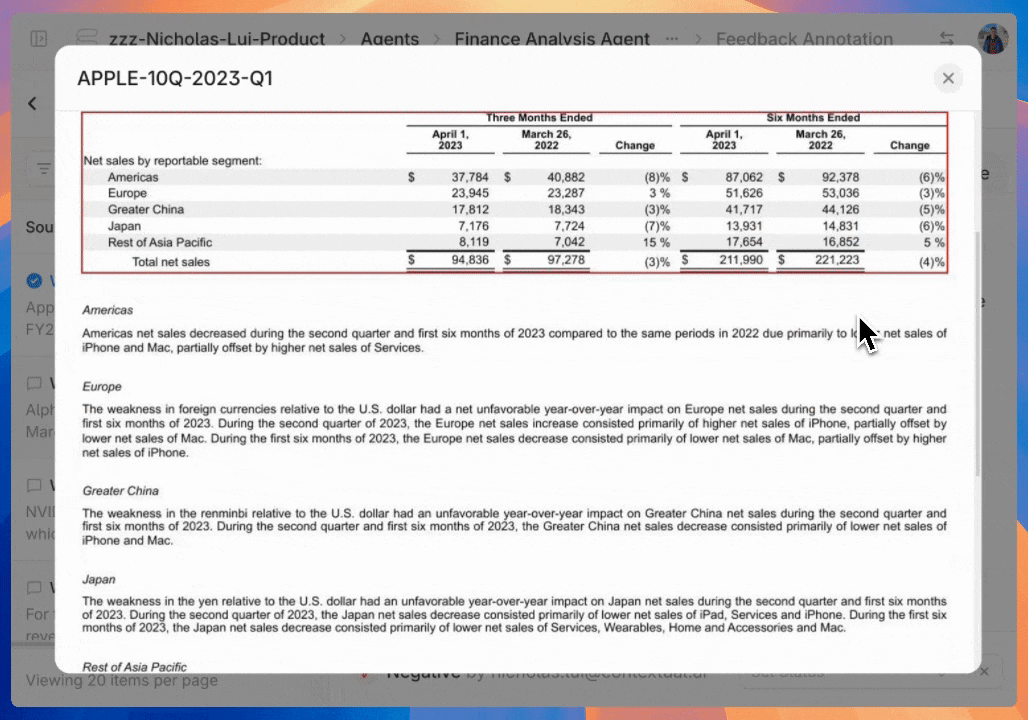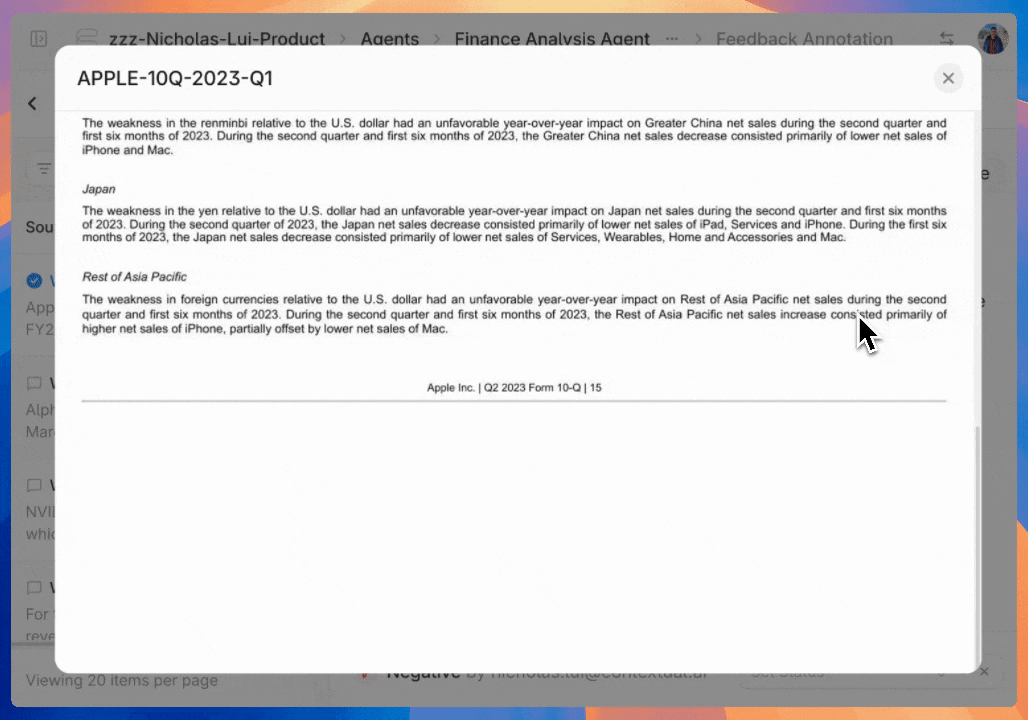
Automatically generated charts and graphs provide instant visibility of any annotation categories trends within a selected time period.

Export data as a CSV anytime to share with other teams or integrate with external systems.

Start improving and try it out
Human evaluation is critical for agent improvement but shouldn't require manual work and constant tool-switching. This new workflow unifies fragmented processes in one platform, delivering granular customization, automation, and intuitive annotation.
Read the documentation and get started!


