Introducing RAG 2.0
Today, we’re announcing RAG 2.0, our approach for developing robust and reliable AI for enterprise-grade performance. Unlike the previous generation of RAG, which stitches together frozen models, vector databases, and poor quality embeddings, our system is optimized end to end.
Using RAG 2.0, we’ve created our first set of Contextual Language Models (CLMs), which achieve state-of-the-art performance on a wide variety of industry benchmarks. CLMs outperform strong RAG baselines based on GPT-4 and the best open-source models by a large margin, according to our research and our customers.
In this blog post, we share our progress in building generative AI systems that go beyond demos to truly production-grade systems:
- We introduce the distinction between RAG, which uses frozen off-the-shelf models, and RAG 2.0, which end-to-end optimizes the language model and retriever as a single system.
- We demonstrate that RAG 2.0 achieves state-of-the-art performance on a wide variety of benchmarks, from open domain question-answering to faithfulness, significantly outperforming existing RAG approaches.
- We highlight even bigger gains for RAG 2.0 on real-world customer workloads and discuss its viability in production.
We’re excited to build with you on RAG 2.0 — join our waitlist today.
Why RAG 2.0?
Language models struggle with knowledge-intensive tasks because they are limited by the information they have been exposed to during training. In 2020, our co-founder and CEO Douwe Kiela and his team at Facebook AI Research introduced Retrieval-Augmented Generation (RAG) to mitigate this problem, by augmenting a language model with a retriever to access data from external sources (e.g. Wikipedia, Google, internal company documents).
A typical RAG system today uses a frozen off-the-shelf model for embeddings, a vector database for retrieval, and a black-box language model for generation, stitched together through prompting or an orchestration framework. This leads to a “Frankenstein’s monster” of generative AI: the individual components technically work, but the whole is far from optimal. These systems are brittle, lack any machine learning or specialization to the domain they are being deployed to, require extensive prompting, and suffer from cascading errors. As a result, RAG systems rarely pass the production bar.
The RAG 2.0 approach pretrains, fine-tunes, and aligns all components as a single integrated system, backpropagating through both the language model and the retriever to maximize performance:

The history of deep learning has repeatedly shown that end-to-end optimization outperforms hand-tuned systems. We apply this approach to move beyond the limitations of RAG and have developed RAG 2.0. To sum it up: if you know that you are going to be doing RAG, you should train the system for doing RAG.
RAG 2.0 Benchmarks
We compared Contextual Language Models (CLMs) with frozen RAG systems across a variety of axes:
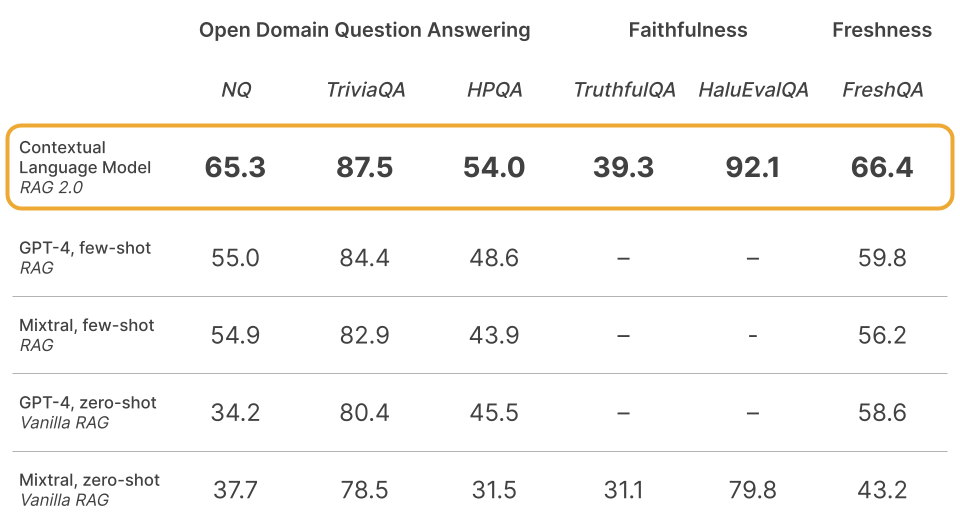
- Open domain question answering: We use the canonical Natural Questions (NQ) and TriviaQA datasets to test each model’s ability to correctly retrieve relevant knowledge and accurately generate an answer. We also evaluate models on the HotpotQA (HPQA) dataset in the single-step retrieval setting. All datasets use the exact match (EM) metric.
- Faithfulness: HaluEvalQA and TruthfulQA are used to measure each model’s ability to remain grounded in retrieved evidence and hallucinations.
- Freshness: We measure the ability of each RAG system to generalize to fast-changing world knowledge using a web search index and show accuracy on the recent FreshQA benchmark.
Each of these axes is important for building production-grade RAG systems. We show that CLMs significantly improve performance over a variety of strong frozen RAG systems built using GPT-4 or state-of-the-art open-source models like Mixtral.
We trained and deployed our RAG 2.0 models on the latest generation of ML infrastructure from Google Cloud. Using A3 instances with H100 GPUs and the latest TCPx networking stack, we were able to train RAG 2.0 models at scale to achieve state-of-the-art accuracy.
Applying RAG 2.0 in the wild
CLMs achieve even bigger gains over current approaches when applied to real world data, as we have seen with our early customers.
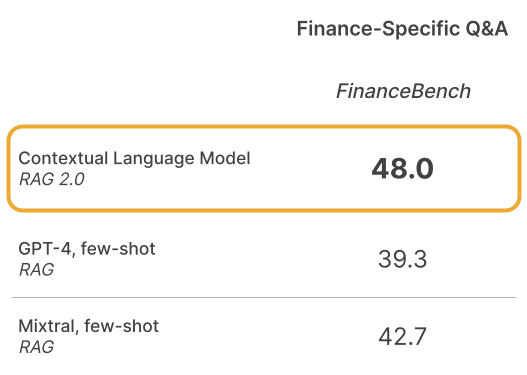
Taking FinanceBench as an illustrative proxy (to maintain the confidentiality of our customers’ data), we can see that CLMs outperform frozen RAG systems even on finance-specific open book question answering — and have seen similar gains in other specialized domains such as law and hardware engineering.
RAG 2.0 and long context windows
When evaluating real world implementations, some may wonder how RAG 2.0 compares to the latest models with long context windows — so we dove into this as well.
Long context models are typically evaluated with “Needle in a Haystack” benchmarks wherein a “needle” (i.e., a fact) is hidden within a large “haystack” (i.e., a corpus of text), and models are evaluated with a query that aims to elicit the particular needle. In an effort to meaningfully compare frozen RAG and Contextual Language Models, we adapt the recent Biographies benchmark by creating a non-repeated haystack of 2M tokens. Using a test set of 100+ biographical questions, we evaluate CLM, Frozen-RAG, and GPT-4-Turbo (only up to 32K tokens) with haystacks ranging from 2K to 2M tokens.
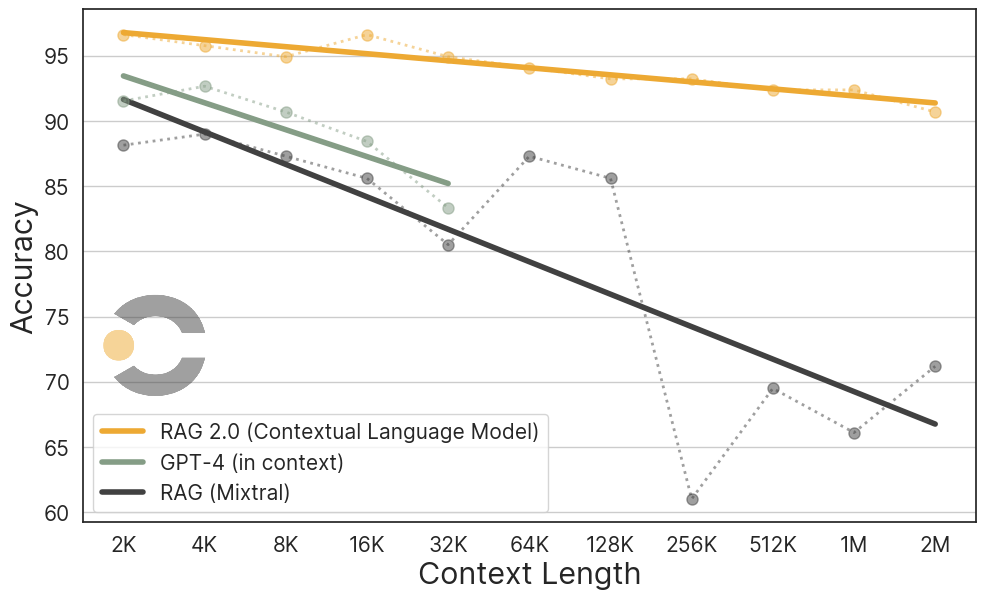
What we see is that RAG 2.0 outperforms, especially if you hope to scale: RAG 2.0 is higher in accuracy and uses substantially less compute compared to long context language models, a difference that becomes meaningful in production.
Build on RAG 2.0 with us
We believe it takes an end-to-end solution to unleash the full potential of generative AI in the enterprise. We are thrilled about the results we’re already seeing with RAG 2.0 and can’t wait to bring it to more leading enterprises.
Fortune 500s and unicorns alike are already building on RAG 2.0 today with Contextual; they are leveraging CLMs and our latest fine-tuning and alignment techniques (such as GRIT, KTO, and LENS) on the Contextual platform to deploy generative AI they can trust in production.
Ready to move beyond demos and use AI in production? We’re actively prioritizing onboarding from our waitlist. If you’re eager to innovate with RAG 2.0, reach out at rag2@contextual.ai and tell us a bit about your use case, or join our waitlist.
Psst, we’re also hiring! If you want to join a world-class team to change the way the world works one workflow at a time, please check out our Careers page.