
Today, we’re releasing a method called Kahneman-Tversky Optimization (KTO) that makes it easier and cheaper than ever before to align LLMs on your data without compromising performance. The success of LLMs has been driven in no small part by alignment with human feedback. If ChatGPT has ever refused to answer your question, it’s likely because it has been trained to avoid saying something controversial. However, it has historically been difficult for companies to align their own LLMs. We’re excited to introduce the KTO method for improving the overall performance and quality of LLMs, while also saving on costs.
Aligning LLMs at scale
LLM alignment is critical for optimizing performance, however it has been difficult because:
- The standard alignment method, Reinforcement Learning with Human Feedback (RLHF), has many moving parts. Open-source efforts have struggled to get it working.
- Alignment methods expect feedback in the form of preferences (e.g., Output A is better than B for input X). Utilizing human annotation efforts for this feedback quickly gets very expensive, and can also result in conflicting data. Humans themselves rate subjectively and thus extensive efforts are needed to define how Output A is quantitatively better than Output B.
These two factors meant that aligning your own LLM at scale was historically a non-starter for most organizations. But the gap is narrowing. Stanford researchers recently tackled the first problem with a technique called Direct Preference Optimization (DPO), which is mathematically equivalent to RLHF while being much simpler, making alignment feasible for open-source efforts.
The remaining bottleneck is data. There are only a handful of public datasets containing human preferences over text, and they are generic. For example, if you want human feedback on which of two LLM outputs more accurately judges the state of the Italian economy, you need to ask a professional. But getting such data is expensive, whether you pay for it outright or ask your employees to spend valuable time providing feedback.
Overcoming the data bottleneck
At Contextual AI, we’ve figured out how to overcome this data bottleneck. By studying the work of economists Kahneman & Tversky on human decision-making, we’ve designed an alignment method that does not require preferences like ‘Output A trumps output B for input X’. Instead, for an input X, we simply need to know whether an output Y is desirable or undesirable. This kind of singleton feedback is abundant: every company has customer interaction data that can be marked as desirable (e.g., sale made) or undesirable (e.g., no sale made).
Kahneman-Tversky Optimization matches or exceeds (state-of-the-art) DPO performance without using preference data. (see technical details in the report and paper)
We compared KTO to existing methods by aligning models from 1B to 30B on a combination of three public datasets: Anthropic HH, Stanford Human Preferences, and Open Assistant. Then we followed a now standard practice of using GPT-4 to compare the aligned model’s generations with the human-preferred baseline provided in the dataset.
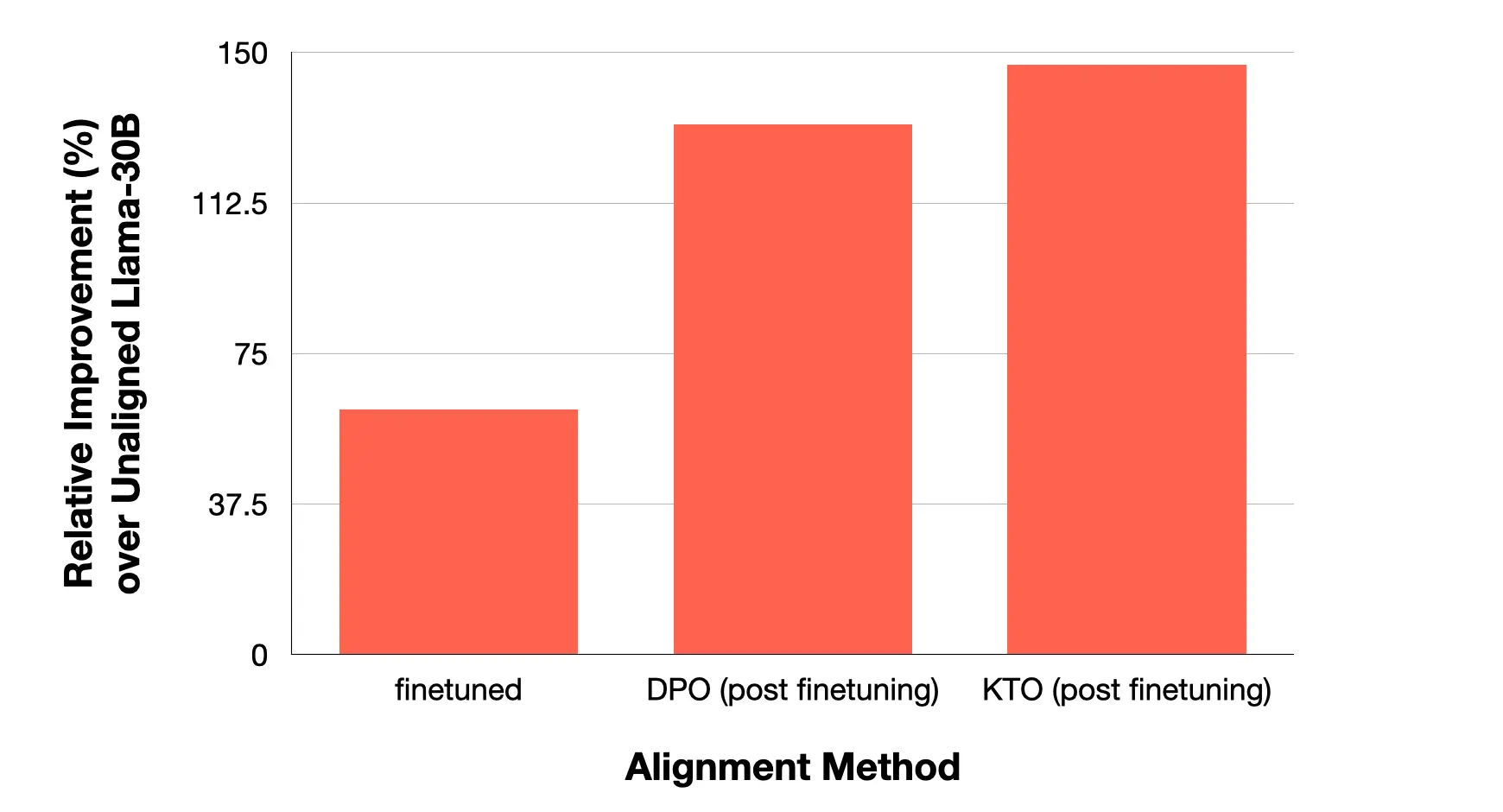
Kahneman-Tversky Optimization provides a big increase in performance over the unaligned model, both over standard finetuning and DPO.
Archangel: open-sourcing 56 models for research
We are also releasing Archangel, the largest-ever suite of human-feedback aligned language models. Archangel comprises 56 models in total: 7 different sizes from 1B to 30B aligned with 8 different methods on 3 of the largest public human feedback datasets. This will enable researchers to ask questions like:
- How does aligning models improve performance at different scales?
- Does model helpfulness and harmlessness — the two thrusts of alignment — scale equally?
- Why are some alignment methods more performant than others?
- How important is the quality of the pretrained model?
All our models can be found on our page on Huggingface, and the code used to create Archangel can be found in our open-source repository.
How do I get started?
- If you’re an engineer who wants to start aligning your own models, check out our open-source repository for KTO-aligning LLMs at scales from 1B to 30B. We make it easy to add your own data and make custom changes to KTO.
- If you’re looking for models that have already been aligned with KTO, check out our page on Huggingface, where we have models from 1B to 30B aligned on public data.
- If you’re interested in having a custom LLM for your company that is customized for your business, please reach out to our product team at info@contextual.ai.
- If you’re interested in joining Contextual AI, please see our careers page.