Vision Augmented Language Models: Computer vision through the LENS of natural language

As humans, we often experience moments that are difficult to put into words alone — from the subtle body language during business negotiations to the joy of witnessing a baby’s first steps.
Can we equip large language models (LLMs) with the ability to see, like humans do?
Current multimodal models that reason about images need additional data and compute resources for extra training rounds, slowing down the addition of visual capabilities to the cutting-edge LLMs. Is it possible to leverage the capabilities of any LLM directly?
We published new research, code and a demo that shows we can enable any LLM available to see through the lens of small, simple vision modules! Surprisingly, this simple method performs better or competitively than state-of-the-art multimodal models on a variety of benchmarks.
Introducing LENS🔍
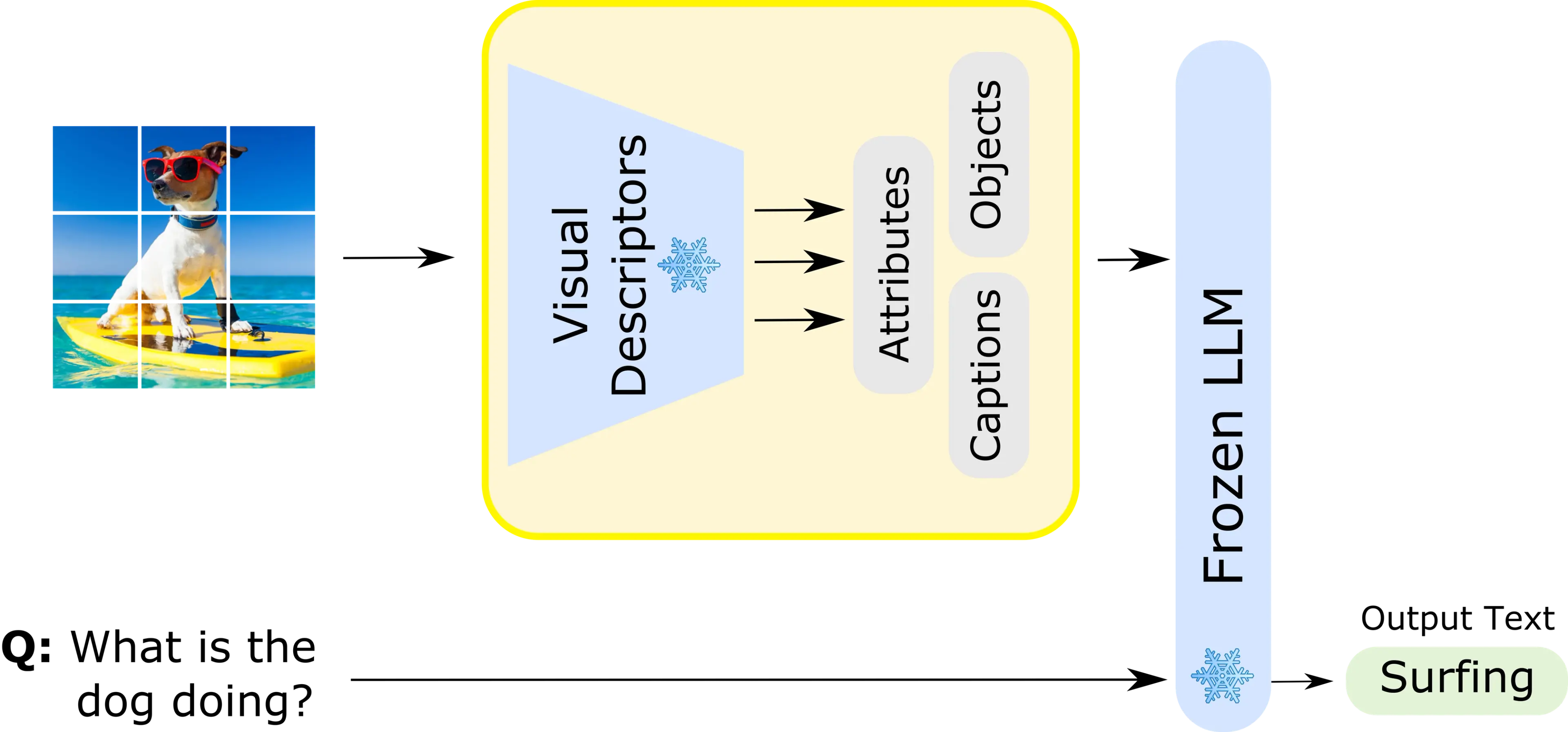
In the preprint today, we present LENS (Large Language Models ENhanced to See), a modular approach that combines the power of independent vision modules and LLMs to enable comprehensive multimodal understanding. LENS embodies the essence of the adage “a picture is worth a thousand words” by passing text generated from small vision modules to a larger LLM. While it is an incredibly simple idea, we find it to be a very strong baseline model.
LENS is competitive with popular multimodal models such as Flamingo and BLIP-2. This is remarkable because we didn’t explicitly train the LLM in LENS to reason about images. Typically, models like Flamingo and BLIP-2 are trained end-to-end for image understanding on large amounts of vision and language data, requiring a lot of data and compute. Below, you can see an example of LENS answering a question about an image. Here, LENS gets visual information as text from a set of simple vision modules. To get the answer to questions, it passes both the visual information and the question to an LLM.
Now let’s see some real examples of the system in a conversational setting!
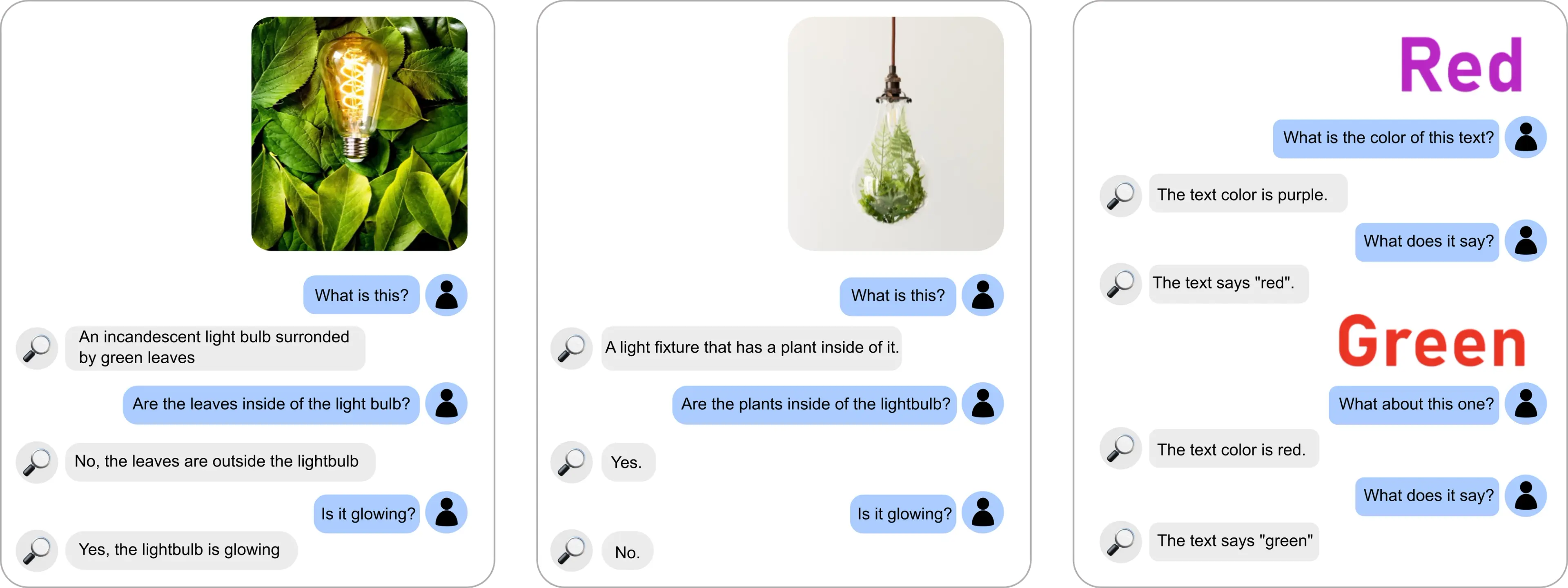
It is impressive that LENS can solve these hard conversational problems in some cases.
Limitations
While LENS is formidable against strong competitors like Flamingo and BLIP-2, this is an area of active research and the model still fails a lot. One cool property about LENS is that we can see the vision model outputs that are fed into the LLM. This means that we can determine whether a failure happened in the vision modules, the LLM, or both.
Let’s take a look at a few of the failure categories.
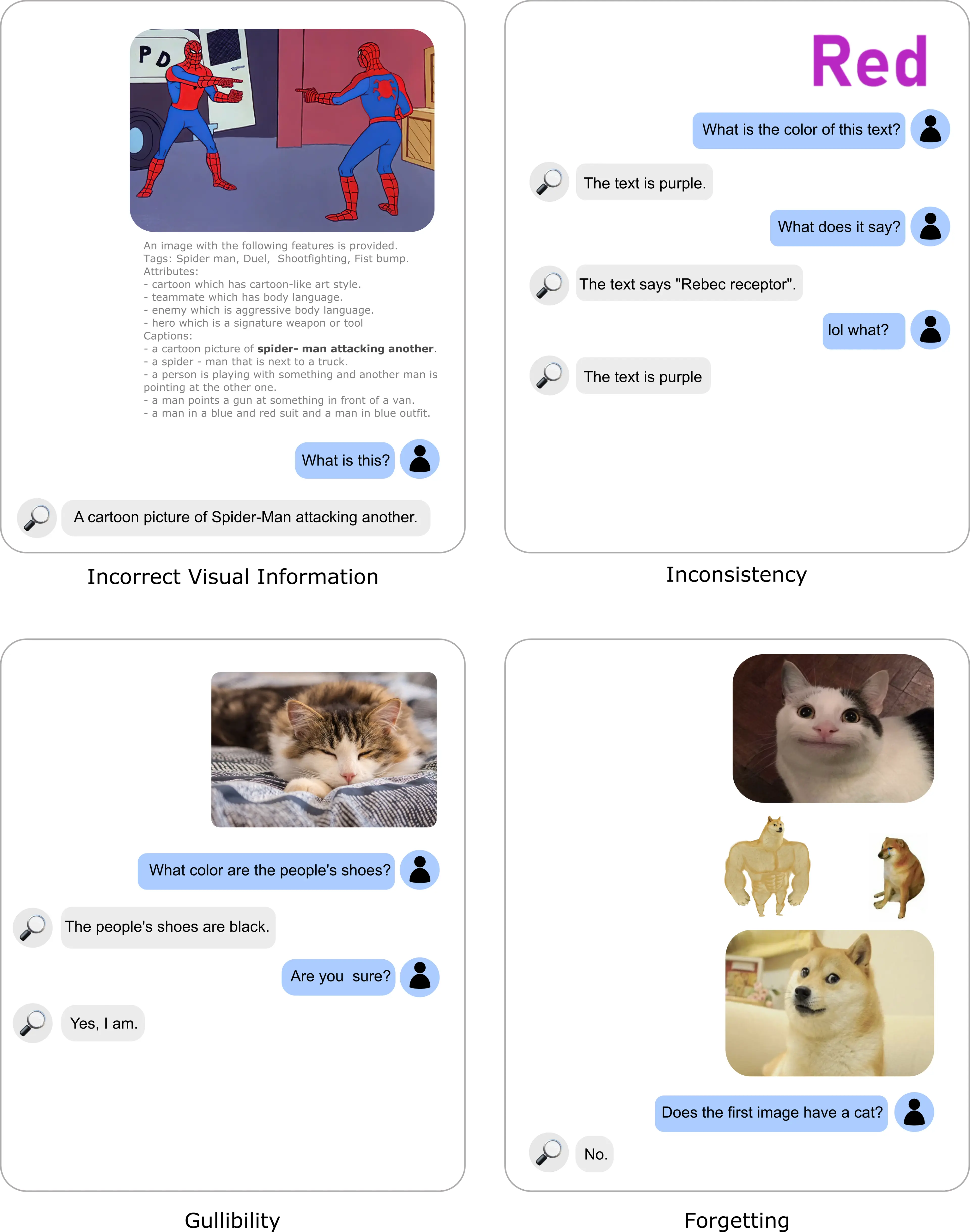
- Incorrect Visual Information (Vision failure): Sometimes the visual descriptions are just wrong. You can see all of the captions from the vision modules for an image of the classic Spider-Man meme. The LLM can’t perform good reasoning with these captions.
- Inconsistency (Both an LLM and vision failure): The model can produce inconsistent results. You can see the model failing on one of the same images from our “good” examples above.
- Gullibility (LLM failure): The LLM can be gullible. It might believe false assumptions that you make about an image. For example, if you give it a picture of a cat and ask what color the people’s shoes are, it may answer “black”. This happens even when the vision modules say nothing about people or shoes.
- Forgetting (LLM failure): LLMs have a limited context window: at some point, they cannot remember all of the conversation history or all of the visual tags. The visual tags from just one image take quite a lot of context.
- Harmful Outputs (Both an LLM and vision issue): The models which make up LENS are typically trained on samples from the internet, which may contain harmful content, such as stereotypes or misinformation.
Try it out!
While LENS has its limitations, it serves as a strong baseline for multimodal model development by harnessing the power of the strongest LLMs to tackle vision and vision-language tasks. For now, we hope that this system is at least advanced enough to make you smile 😃. Try it out yourself, have fun, and help us make multimodal models even stronger!