
RAG is dead, long live RAG!
Every few months, the AI world experiences a similar pattern. A new model drops with a larger context window, and social media lights up with declarations that “RAG is dead.” Meta’s latest breakthrough has sparked this conversation again—Llama 4 Scout’s staggering 10M token context window (on paper) represents a genuine leap forward.
But these pronouncements—whether for a context window breakthrough, a fine-tuning advancement, or the emergence of Model Context Protocol (MCP)—misunderstand RAG’s purpose and why it will always have a role in AI.
What RAG Was Always About
Five years ago, my team at Meta Fundamental AI Research (FAIR, previously Faceboook AI Research) came up with the concept of RAG. The goal for RAG was to augment models with external knowledge, creating a best-of-both-worlds solution that combined parametric and non-parametric memory.
In simple terms, RAG extends a language model’s knowledge base by retrieving relevant information from data sources that a language model was not trained on and injecting it into the model’s context.
The approach was meant to address a lot of the shortcomings of generative language models:
- No access to private (internal enterprise) data: Models are trained on public data, but often need proprietary information that’s constantly changing and expanding.
- Outdated parametric knowledge: Even with frequent model updates, there’s always a gap between the model’s training cutoff and the present day.
- Hallucinations and attribution issues: Models often invent plausible-sounding but incorrect information. RAG solves this by grounding responses in real sources and providing citations to let users verify the information.
Sound familiar? It’s not 2020 anymore, but these same problems exist today. If anything, they’ve become more pronounced as organizations push AI systems to handle increasingly complex and critical tasks. The core challenge remains: how do we connect powerful generative models with the vast knowledge stores that companies depend on?
Why We Still Need RAG (And Always Will)
Efficient and precise retrieval will always play a role in AI. This was well articulated in a widely-shared LinkedIn post, but I’ll restate the reasons we can’t just load all of your data into your model’s context:
Scalability – Your enterprise knowledge base is measured in terabytes or petabytes, not tokens. Even with 10M token context windows, you’re still only seeing a tiny fraction of your available information. This is why innovation in retrieval techniques has continued at a fast pace, with advances in hybrid search, query transformations, self-reflection, active retrieval, and support for structured data helping to find the right information in your knowledge base.
Accuracy – The effective context windows are far different than what is advertised in product launches. Research consistently shows performance degradation long before models reach their official limits. In real-world testing, the same pattern emerges, with models struggling to accurately reference information buried deep in their contexts. This “context cliff” means simply stuffing more content into the window won’t translate to better results.
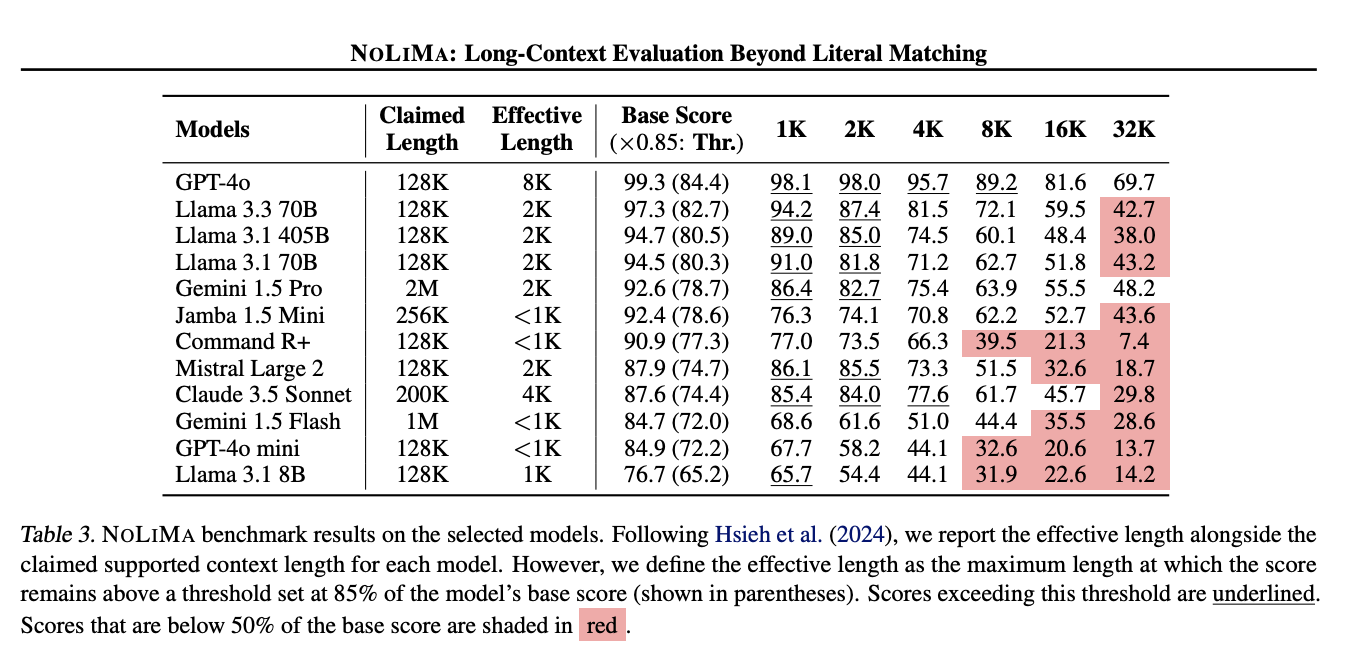
Latency – Loading everything into the model’s context leads to significantly worse response times. For user-facing applications, this creates a bad experience where people abandon the interaction before getting their answer. Retrieval-based approaches can deliver faster responses by adding only the most relevant information.
Efficiency – Do you read an entire textbook every time you need to answer a simple question? Of course not! RAG provides the equivalent of jumping straight to the relevant page. Processing more tokens isn’t just slower—it’s also wildly inefficient and way too expensive than using RAG to pinpoint just what you need.
Beware of False Dichotomies
Search “RAG vs” in Google, and you’ll find a long list of suggested query completions—”long context”, “fine-tuning”, and “MCP”. This framing creates an artificial choice that doesn’t reflect how these technologies actually work best together.

In reality, none of these are mutually exclusive or even conflicting concepts—they all help with addressing the limitations of frontier models in complementary ways:
- RAG provides access to information outside the model’s knowledge
- Fine-tuning improves how that information is processed and applied
- Longer contexts allow for more information to be retrieved for the model to reason over
- MCP simplifies agent integrations with RAG systems (and other tools)
The most sophisticated AI systems we’re seeing in production combine these approaches, using each tool where it offers the most advantage rather than declaring one the winner and discarding the rest.
As one Twitter user recently put it: “Claiming that large LLM context windows replace RAG is like saying you don’t need hard drives because there’s enough RAM.” Exactly! Your computer has disk, RAM, and a network card for a reason. They serve different purposes and work together as a system. The same goes for RAG, fine-tuning, and large context windows in AI.
Conclusion
We don’t need to choose between RAG and long context windows, fine-tuning, or MCP. The AI solutions that actually deliver value don’t get fixated on a single approach; they mix and match tools based on the specific problems they’re solving.
But it’s only a matter of time before the next proclamation that “RAG is dead”, so if you ever want to reference this post, you can find it at isragdeadyet.com. The site will remain a living testament to the enduring importance of retrieval in AI systems, updated whenever the next wave of “RAG is dead” posts inevitably appears.
If your systems can’t tap into your proprietary data, keep serving up outdated information, or lack the specialized knowledge you need, let’s talk. We’ve built something that brings together smart retrieval with cutting-edge LLMs to tackle these persistent headaches. Because what matters isn’t which tech wins some artificial horse race—it’s building stuff that actually works for real problems.