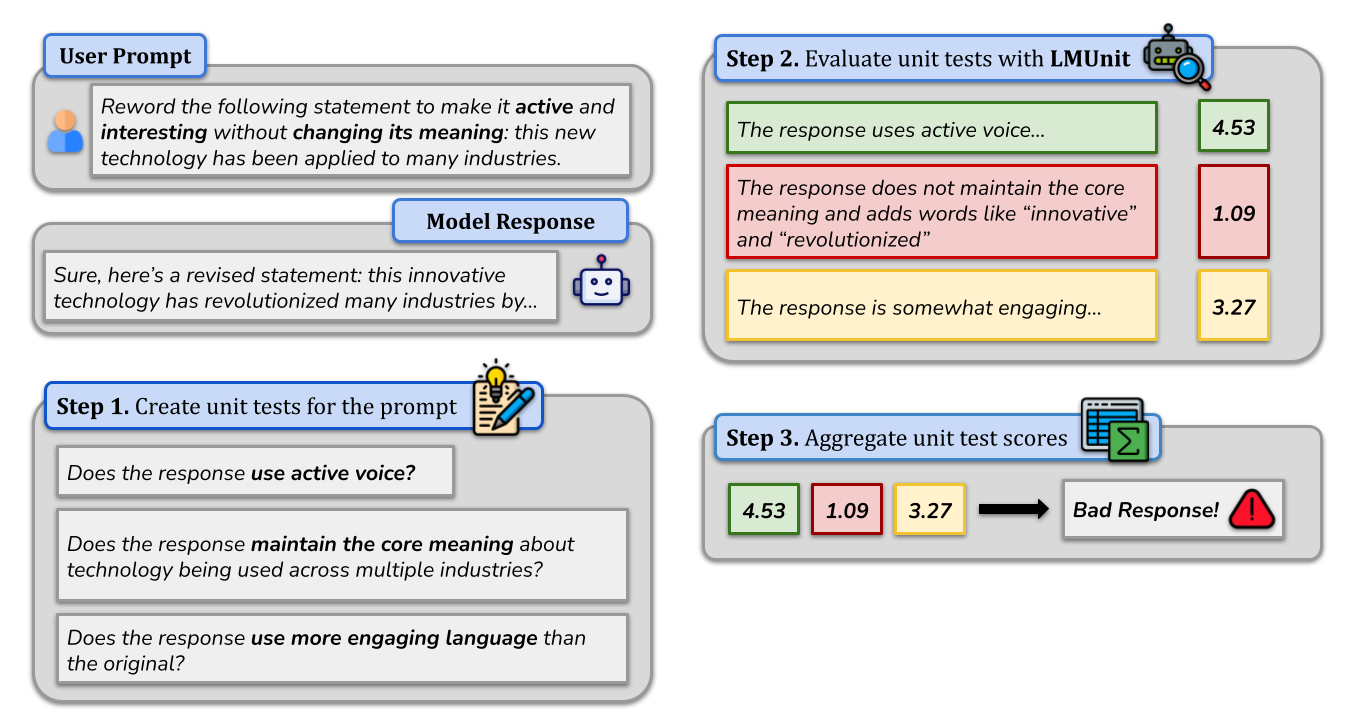
Introducing LMUnit: Natural language unit testing for LLM evaluation
Today, we’re excited to introduce natural language unit tests, a new paradigm that brings the rigor, familiarity, and accessibility of traditional software engineering unit testing to Large Language Model (LLM) evaluation. In this paradigm, developers define and evaluate clear, testable statements or questions that capture desirable fine-grained qualities of the LLM’s response – such as “Is the response succinct without omitting essential information?” or “Is the complexity of the response appropriate for the intended audience?” By doing so, developers gain insights into model performance, similar to how traditional software unit tests check individual functions. This approach enables precise diagnosis of issues and a deeper understanding of their underlying causes, streamlining the improvement and debugging process of LLM applications.
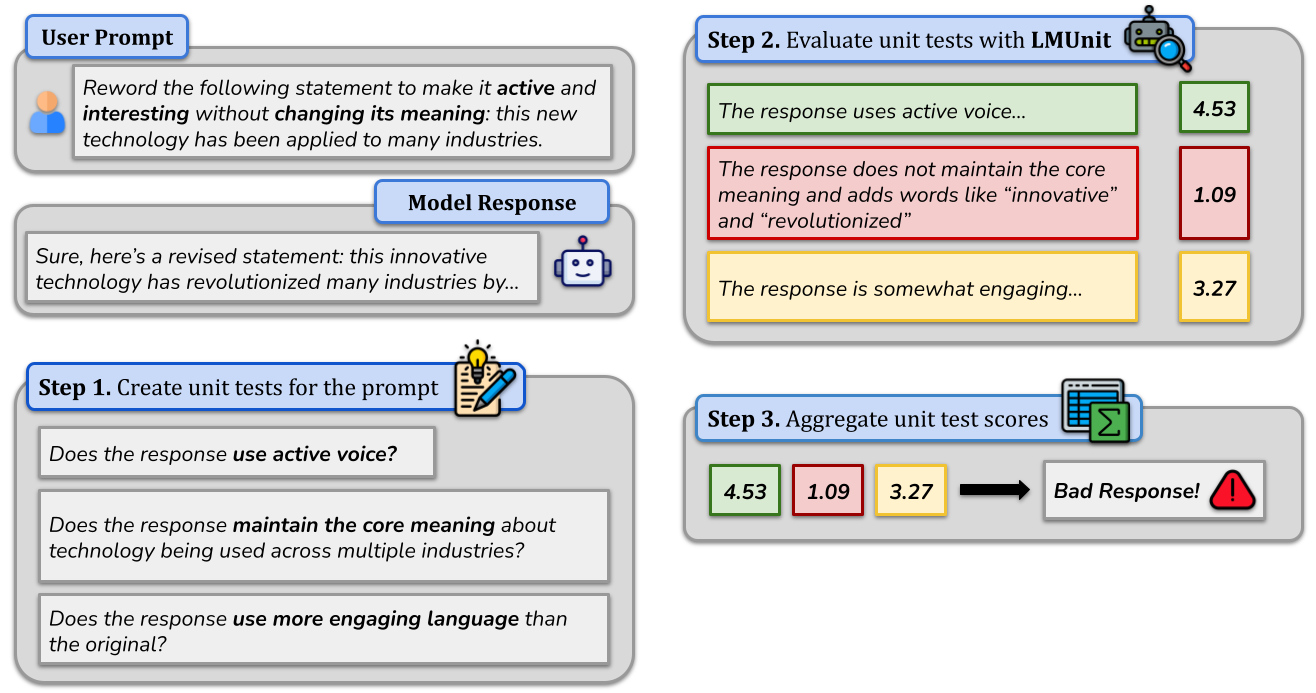
As an implementation of this paradigm, we’re introducing LMUnit, a language model optimized for evaluating natural language unit tests. LMUnit achieves leading averaged performance across preference, direct scoring, and fine-grained unit test evaluation tasks. Optimized specifically for unit test evaluation, LMUnit outperforms large frontier models like GPT-4 and Claude-3.5-Sonnet, while providing greater interpretability at a lower cost. LMUnit sets the state of the art for fine-grained evaluation, as measured by FLASK and BiGGen Bench, and performs on par with frontier models for coarse evaluation of long-form responses (per LFQA). The model also demonstrates exceptional alignment with human preferences, ranking in the top 5 of the RewardBench benchmark with 93.5% accuracy.
While AI has become increasingly accessible to developers through APIs for embeddings and language models, its evaluation remains a complex challenge. Human annotation is noisy, automatic metrics provide limited insights, and general-purpose LLMs exhibit implicit biases and often perform below specialized models. LMUnit addresses these issues by providing a systematic and accessible approach to LLM evaluation.
Implementing natural language unit tests and evaluating them with LMUnit makes LLM evaluation accessible to both developers and non-technical counterparts by applying the familiar principles of unit testing to LLMs. This is a critical development that will expedite the safe deployment of LLMs in high-stakes production settings, accelerating AI’s transformational impact across industries.
We are excited to release LMUnit for public use through the Contextual API. Check out our Getting Started section to start experimenting with LMUnit!
The Evaluation Challenge
The rapid advancement of LLMs has created a significant challenge: how do we rigorously and thoroughly evaluate these increasingly sophisticated systems at scale? While developers can now easily integrate LLM capabilities through simple API calls, evaluation is still a difficult challenge even for machine learning experts.
LLM evaluation primarily happens in a few forms:
- Direct scoring: Given a query, an LLM response, and evaluation criteria, score the response according to the criteria.
- Reference-based scoring: Given a query, a reference response (often called the “gold” response), and an LLM response, compare the reference and LLM responses.
- Pairwise comparison: Given a query and two LLM responses, rank the responses.
Current methods for executing the above LLM evaluation approaches have significant shortcomings:
- Human annotations are expensive, time-consuming, and often suffer from inconsistency between annotators.
- Automatic metrics like ROUGE and BLEU only capture surface-level text similarity against a gold response, failing to assess deeper qualities like reasoning, factuality, and coherence.
- Reward Models (RM) are difficult to interpret and adjust after training, often reducing complex quality dimensions into a single score. They are sensitive to training data bias and can learn unintended preferences (e.g., favoring longer responses).
LM judges, language models that judge responses, enable evaluation through natural language instructions, reducing the need for ML expertise. However, using general-purpose frontier models as judges often fails to provide fine-grained, high-resolution feedback that pinpoints exact areas of improvement. In addition, such models can be unnecessarily expensive and fall behind specialized models in evaluation performance.
Natural Language Unit Tests
The natural language unit test paradigm is simple, cost-effective, and compatible with existing testing frameworks.
A unit test is a specific, clear, testable statement or question in natural language about a desirable quality of an LLM’s response. Just as traditional unit tests check individual functions in software, unit tests in this paradigm evaluate discrete qualities of individual model outputs – from basic accuracy and formatting to complex reasoning and domain-specific requirements. Global unit tests can be applied to all queries in an evaluation set, e.g., “Does the response maintain a formal style?”. Targeted unit tests can offer a focused assessment of query-level details. For example, a targeted unit test for the query “Describe Stephen Curry’s legacy in the NBA” could be “Does the response mention that Stephen Curry is the greatest shooter in NBA history?”
We encourage developers to define unit tests that align with their preferences and application needs. Developers can also weight unit tests by their relative importance for a given use case, for example, weighting unit tests on safety or reasoning accuracy more highly than other unit tests.
The LMUnit Model
LMUnit is a state-of-the-art language model optimized for evaluating natural language unit tests. In practice, LMUnit is a standard language model that takes three inputs: a prompt, a response, and a unit test. It then produces a continuous score between 1 and 5 where higher scores indicate better satisfaction of the unit test criteria. The model can be further optimized on custom datasets to suit specific use cases.
LMUnit is highly performant and versatile because of key methodologies in its training approach:
- Multi-Objective Training: The model simultaneously learns from multiple evaluation signals, including pairwise comparisons between responses, direct quality ratings, and specialized criteria-based judgments.
- Synthetic Data Generation: We developed a sophisticated pipeline to generate training data that captures nuanced, fine-grained evaluation criteria and subtle quality distinctions between responses across a wide range of use cases and scenarios.
- Importance Weighting: We demonstrate that adjusting unit test weights to reflect the relative importance of different criteria achieves results that better align with human preferences.
Implementing natural language unit tests with LMUnit has several advantages, making it the most reliable and accessible approach to LLM evaluation.
- 💪 Robust performance: LMUnit is state-of-the-art on benchmarks that measure fine-grained details across multiple domains such as FLASK and BigGBench and on par with frontier models at coarse evaluation of Long-form Question Answering (LFQA). In addition, LMUnit outperformed GPT-4o and Claude 3.5 Sonnet by over 9% on scoring unit tests on Human-Internal, our in-house customer dataset containing finance and engineering domains.
- 👱 Alignment with human preference: LMUnit shows strong human alignment across a range of tasks. For example, it achieved 93.5% accuracy on the RewardBench benchmark, which tests evaluation systems’ ability to predict human preferences between different responses to a prompt.
- 🎯 Fine-grained, Actionable Insights: By breaking down evaluation into granular unit tests, LMUnit identifies specific strengths and weaknesses across various response qualities. We conducted a user study of 16 LLM researchers and asked users to compare LMUnit with LM Judge results on the Arena-Hard-Auto benchmark and a domain-agnostic commercial benchmark. Users identified 131% more error modes and 157% more response attributes with LMUnit compared to traditional LM judges and rated these modes and attributes as 33% and 35% more important, respectively. Ultimately, 16/16 users preferred LMUnit over LM judges.
- ⚙️ Production-Readiness: LMUnit’s modularity enables seamless compatibility with CI/CD pipelines, providing real-time feedback in deployed LLM systems. In fact, Contextual already processes tens of thousands of evaluation instances for our customers, which helps us rapidly diagnose failure modes and robustly improve application performance for our customers.
- 👪 Accessibility to Non-Technical Stakeholders: Unit tests written in natural language allow both technical and non-technical team members to specify and understand evaluation criteria. This enables true test-driven development for AI systems while maintaining the rigor of software engineering practices.
Getting Started
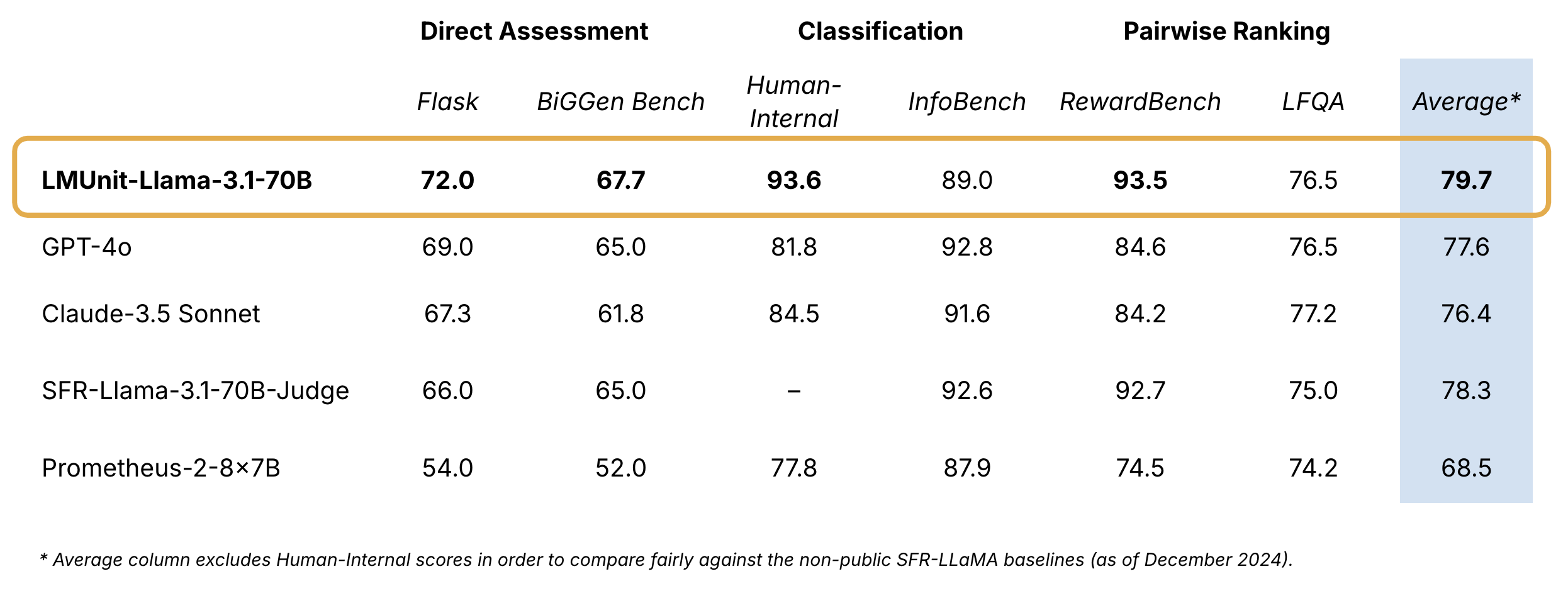
LMUnit is available for free through the Contextual API. Please fill out this form, and we will send you an API key for interacting with the LMUnit model.
Sample code:
Ready to uplevel your LLM evaluation? Start using LMUnit today! If you need support or have any feedback, please email LMUnit-feedback@contextual.ai
Links
Built with Meta Llama 3. (License)