Plotting Progress in AI
The last few years have seen relentless progress in what AI can do, yet our ability to gauge these abilities has never been worse. A key culprit? Static benchmarks.
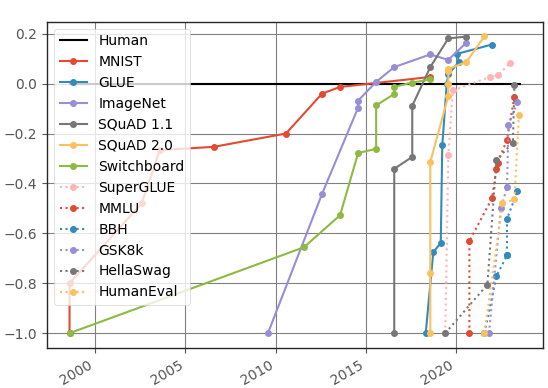
We recognized this problem back in 2021 and argued that benchmarks should be as dynamic as the models they evaluate. To make this possible, we introduced a platform called Dynabench for creating living, and continuously evolving benchmarks. As part of the release, we created a figure that showed how quickly AI benchmarks were “saturating”, i.e., that state of the art systems were starting to surpass human performance on a variety of tasks.
 Source: Kiela et al. (2021). Dynabench. ACL.
Source: Kiela et al. (2021). Dynabench. ACL.
Since then, key scientists and publications have used this figure as a quick way to demonstrate the accelerating progress in AI, such as this Science article published last year.
New plots for a new era
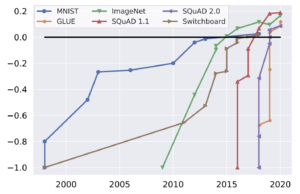
But, now, the plot is hopelessly outdated. With how fast AI has been advancing over the past few years, the datasets feel almost prehistoric. It’s high time for an updated set of plots, with a new set of datasets. Recent progress has mostly been driven by language models, so let’s zoom in on well-known language model evaluation benchmarks in particular:
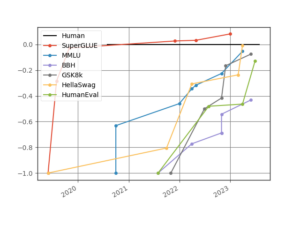
When GLUE was introduced, it was saturated within a year. The same thing happened even faster to SuperGLUE, which was meant to replace it as a longer-lasting alternative. This triggered a response in the field: much harder benchmarks were created. At the same time, due to GPT-3’s demonstration of in-context learning (and increase in the number of parameters), models were starting to be evaluated in zero or few-shot settings. This leads to comparatively less steep curves, albeit slightly.
Still, we see that with the recent progress, benchmarks are again rapidly approaching saturation. Very challenging datasets like HellaSwag are basically solved now. Only BigBench-Hard, a challenging subset of BigBench, still has relatively lower performance compared to its original baseline numbers when compared to human performance.
Zooming Out
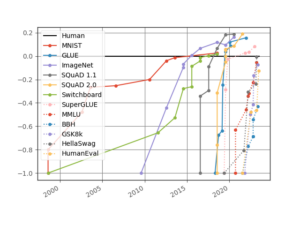
By overlaying the new numbers on top of the old figure, we can observe that the rate of change from a benchmark being introduced to it being solved is still significantly different from what it was like before the AI revolution:
Explainer: How were these numbers calculated?
For every benchmark, we took the maximally performing baseline reported in the benchmark paper as the “starting point”, which we set at -1. The human performance number is set at 0. In sum, for every result X, we scale it as (X-Human)/Abs(StartingPoint-Human). Finding results was made much easier by Paperswithcode.
The State of Benchmarking
There is now a widespread consensus that AI is bottlenecked by proper benchmarking. This includes doing rigorous human evaluation and “red teaming” models to reveal and address model weaknesses. There has also been a push towards more holistic benchmarking, such as in Stanford’s HELM (and as originally argued for in Dynaboard). Rolling out models over time is essentially a community-wide dynamic adversarial benchmarking process, where new benchmarks are created based on the failure modes of the current state-of-the-art, ever pushing forward the capabilities of our systems.
Dynabench itself is now owned by MLCommons (Meta transferred ownership in 2022), the open engineering consortium with a mission to benefit society by accelerating AI innovation. The platform is still going strong: in addition to the original tasks, it has hosted challenges like Flores, DataPerf and BabyLM. The dynamic adversarial datasets introduced by the platform remain far from solved, and more importantly, the philosophy of adversarial and holistic benchmarking pioneered in Dynabench, Dynaboard, and GEM is now becoming more mainstream.
Just getting started
Evaluation is never an easy topic. A recent example is the big difference in how language models were ranked on different leaderboards purportedly reporting the same thing. Tiny changes in simple evaluation metrics can lead to very different results. There is no agreed-upon standardized framework and we’ve resorted to using language models to evaluate other language models. Innovative companies are looking at doing a better job here, like Patronus.
AI is just getting started. Language models are great first generation technology, but still have very important shortcomings. Some of these are borne out by evaluation benchmarks, but the research community doesn’t even know how to evaluate many aspects of LLMs in the first place.
At Contextual AI, we’re actively solving key limitations for enterprises looking to bring LLM-powered products to customers at scale, including attributions, hallucinations, data staleness, and privacy. After static test sets, dynamic benchmarking, red teaming, ELO ratings, and tools from developmental psychology, there is still a lot more work to be done in properly evaluating LLMs, especially when it comes to critical settings.
Important issues like hallucination, attribution and staleness are going to be solved in the not too distant future. Privacy will improve and the cost will go down. These are exciting times that we live in. Who knows what our plots will look like a few years from now?
Citation: If you found this useful for your academic work, please consider citing this blog. BibTex:
@article{kiela2023plottingprogress, author = {Kiela, Douwe and Thrush, Tristan and Ethayarajh, Kawin and Singh, Amanpreet}, title = {Plotting Progress in AI}, journal = {Contextual AI Blog}, year = {2023}, note = {https://contextual.ai/blog/plotting-progress}}