
Today, we’re introducing our Grounded Language Model (GLM), the most grounded language model in the world. With state-of-the-art performance on FACTS (the leading groundedness benchmark) and our customer datasets, the GLM is the single best language model for RAG and agentic use cases for which minimizing hallucinations is critical. You can trust that the GLM will stick to the knowledge sources you give it. To get started for free today, create a Contextual AI account, visit the Getting Started tab, and use the /generate standalone API!
In enterprise AI applications, hallucinations from the LLM pose a critical risk that can degrade customer experience, damage company reputation, and misguide business decisions. Yet the ability to hallucinate is seen as a useful feature in foundation models to serve consumer queries that require creative, novel responses (e.g., “Tell me an imaginary story about the Warriors”). In contrast, the GLM is engineered specifically to minimize hallucinations for RAG and agentic use cases – delivering precise responses that are strongly grounded in and attributable to specific retrieved source data, not its parametric knowledge learned from training data. Uniquely, the model also provides inline attributions, citing the sources of retrieved knowledge directly within its responses as they are generated. These attributions enable users to track precisely where each piece of information originates. Foundation models fall short; even when provided the exact correct information, they still often hallucinate or prefer their own parametric knowledge during response generation.
Contextual’s founding team co-authored the original RAG research paper, and we believe that language models optimized for groundedness are critical to unlocking maximum performance in RAG and agentic applications.
 GET STARTED FOR FREE
GET STARTED FOR FREEThe necessity for groundedness in enterprise AI
“Groundedness” refers to the degree to which an LLM’s generated output is supported by and accurately reflects the retrieved information provided to it. Given a query and a set of documents, a grounded model either responds only with relevant information from the documents or refuses to answer if the documents are not relevant. In contrast, an ungrounded model may hallucinate based on patterns learned from its training data.
While many efforts to improve groundedness focus on retrieving the right information to pass to language models, we’ve discovered a deeper challenge in enterprise deployments: foundation models frequently hallucinate even when given the correct information. They often favor their pre-trained knowledge over provided retrievals, ignore explicit instructions to stick to given sources, or lose track of context in longer exchanges.
This lack of reliable groundedness creates a mission-critical risk in enterprise AI. When AI systems hallucinate responses that misrepresent company knowledge, they erode user trust. For example:
- Customer support: A customer service AI might confidently state a false discount policy even when provided the current policy document, such as when Air Canada’s chatbot incorrectly promised a customer a discount.
- Finance: A research AI that hallucinates values from tables and charts in trusted market analysis documents could mislead traders to make bad trades.
- Engineering: A debugging assistant that draws information from general chip schematics instead of those in provided company documentation could mislead an engineer to make a problem worse.
Enterprises struggle building reliable RAG and agentic workflows in part because they use general-purpose foundation models that are not optimized for groundedness.
State-of-the-art groundedness
Our GLM is engineered specifically for RAG and agentic use cases that necessitate high groundedness for reliable deployment, while foundation models are trained for general-purpose use cases and are prone to hallucination. The GLM minimizes the risk of hallucinations by prioritizing faithfulness to retrieved knowledge over information learned during pretraining. Specifically, the model provides inline attributions by integrating source citations directly into its responses as they’re being created. Our empirical results show that the GLM is the best language model to use for RAG and agentic use cases in which faithfulness to company data is table stakes.
The GLM achieves state-of-the-art performance on the Public Set of FACTS, the leading groundedness benchmark, outperforming all foundation models. This benchmark includes a wide range of domains and tasks, supporting GLM’s robust effectiveness.
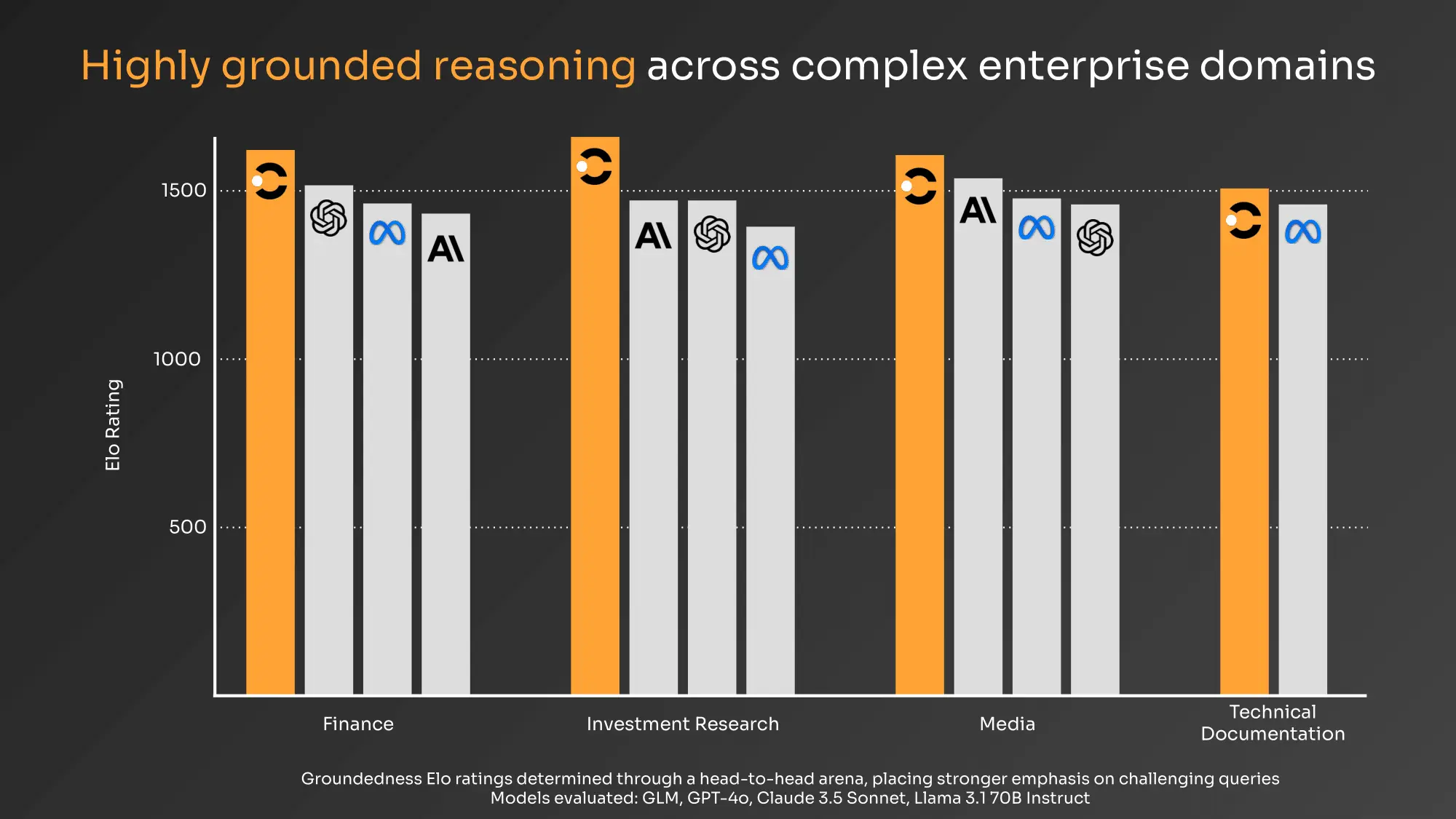
The GLM also outperforms leading foundation models on our proprietary customer benchmarks, demonstrating the GLM’s consistent and significant improvements in grounded reasoning across diverse enterprise contexts. We use four evaluation datasets spanning different customer verticals, curated by our in-house data team to target failure modes commonly observed in complex, noisy enterprise scenarios – where models often struggle to reason effectively over retrieved knowledge. We compute Elo scores through a head-to-head arena, thereby placing stronger emphasis on difficult cases (i.e., correct answers on samples that many other models get wrong yield higher Elo gain).
Getting Started with the GLM
Use the GLM for free today by creating a Contextual AI account, visiting the Getting Started tab, and using the /generate standalone API. We provide credits for the first 1M input and 1M output tokens, and you can buy additional credits as your needs grow. To request custom rate limits and pricing, please contact us here. If you have any feedback or need support, please email glm-feedback@contextual.ai.
Documentation: /generate API, Python SDK, Langchain package – and code examples for each of these!
Avoiding commentary
The GLM has an avoid_commentary flag to indicate whether the model should avoid providing additional commentary in responses. Commentary is conversational in nature, so it is not always strictly grounded in the given knowledge sources, but it can provide context that can improve the helpfulness of the response. This flag enables users to control the groundedness of the response as appropriate for the use case.

Optimizing the GLM with the Contextual AI Platform
Founded by the inventors of RAG, Contextual AI offers a state-of-the-art platform for building and deploying specialized RAG agents. Each individual component of the platform achieves state-of-the-art performance, including document understanding, structured and unstructured retrieval, grounded generation (with the GLM), and evaluation. The platform achieves even greater end-to-end performance by jointly optimizing the components as a single, unified system.
Using the GLM will likely drive significant improvement in your existing RAG and agentic workflows, and using the Contextual AI Platform can provide even further gains. Our platform is generally available and works for a diversity of use cases and settings. Sign up to build a production-ready, specialized RAG agent today!
The GLM is built with Meta Llama 3. (License)


